- Research
- Open access
- Published:
A graphical method for practical and informative identifiability analyses of physiological models: A case study of insulin kinetics and sensitivity
BioMedical Engineering OnLine volume 10, Article number: 39 (2011)
Abstract
Background
Derivative based a-priori structural identifiability analyses of mathematical models can offer valuable insight into the identifiability of model parameters. However, these analyses are only capable of a binary confirmation of the mathematical distinction of parameters and a positive outcome can begin to lose relevance when measurement error is introduced. This article presents an integral based method that allows the observation of the identifiability of models with two-parameters in the presence of assay error.
Methods
The method measures the distinction of the integral formulations of the parameter coefficients at the proposed sampling times. It can thus predict the susceptibility of the parameters to the effects of measurement error. The method is tested in-silico with Monte Carlo analyses of a number of insulin sensitivity test applications.
Results
The method successfully captured the analogous nature of identifiability observed in Monte Carlo analyses of a number of cases including protocol alterations, parameter changes and differences in participant behaviour. However, due to the numerical nature of the analyses, prediction was not perfect in all cases.
Conclusions
Thus although the current method has valuable and significant capabilities in terms of study or test protocol design, additional developments would further strengthen the predictive capability of the method. Finally, the method captures the experimental reality that sampling error and timing can negate assumed parameter identifiability and that identifiability is a continuous rather than discrete phenomenon.
1. Background
A number of physiological phenomenon have been modelled by formulating mathematical representations of the relevant interactions. These models frequently incorporate variable parameters that can be identified to match the model representation to the observed behaviour. The value of these parameters is then used to characterise or quantify the response. However, with complex or large models, variable parameters can be selected that seem mathematically distinct, but in reality define the same observable effect and identification failure is certain. Thus, model identifiability analyses are used to test the selection of model parameters and ensure that they are mathematically distinct.
Approaches for the analysis of model identifiability typically assume continuous perfect input data [1–3]. However, these derivative-based identifiability methods can produce false assurances of identifiability. Recent dissatisfaction with the classical algorithms has resulted in the development of new methods that recognise assay error and discrete measurements as critical to identifiability [4, 5]. The limitation of discrete data that is often subject of assay error often causes parameter trade-off [6–9] and thus limitation of the identified metrics clinical value. Thus, not only should a model be checked for identifiability in the classical a-priori sense, but the susceptibility of parameters to mutual interference should also be tested.
For example, the Minimal Model of insulin sensitivity [10] has been shown to be identifiable using such methods [11–13]. However, with discrete data that is subject to assay error, parameter identification has sometimes failed [6, 7, 14]. Numerous Bayesian techniques have had success in limiting this failure [7, 15–17], but they tend to force the parameters to diverge away from their true least square values, limiting the relevance of the model and exaggerating the influence of population trends on an individual test's identified parameter values. Thus, widespread clinical application of these models has been limited by the ambiguity of results.
This article presents a novel graphical method for identifiability analysis that allows an identifiability analysis with consideration of noise and assay error. Furthermore, the method highlights areas for potential improvements to protocols and sampling times that would improve practical identifiability. At this stage of development, the method is limited to first-order, two-parameter models that allow a separation of parameters, but are typical of those found in pharmacokinetic (PK) and pharmacodynamic (PD) modelling.
2. Method and Study Design
The proposed method will be evaluated in-silico using clinically validated models of insulin kinetics and the dynamic between insulin concentration and glucose decay. The method's ability to predict the variation behaviour of identified parameters in a Monte Carlo analysis will be tested.
2.1 Proposed method process
To evaluate identifiability of a model, the integral formulations of the parameters are evaluated using an estimated test stimulus response. Thus, the method cannot be used in complete ignorance of the expected behaviour of the test participant. In particular, the approximate shape of the species concentrations as a result of the test protocol must be estimated, (this is a reasonable assumption in most PK/PD studies). The specific steps are illustrated using a generalised function:

where: X is a measured species with a discrete resolution, Y is a species that is co-dependent with X and is not measureable, C and D are independent known input profiles, and a and b are unknown model parameters
-
1.
Rearrange governing equation to create a first order differential equation with separated parameters in terms of a-priori, constant and measurable concentration terms
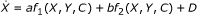 (ii)
(ii) -
2.
Derive the integral formulation of this governing equation
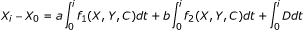 (iii)
(iii)
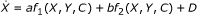
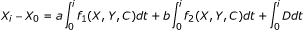
where: i is each measured sample time after the first.
-
3.
Evaluate the integral of the coefficients of each parameter between 0 and each proposed sample time using an assumed participant response to the test stimulus.
 (iv)
(iv) -
4.
Divide the resulting values by their respective means to normalise the coefficients.
 (v)
(v) -
5.
Subtract one set of coefficients from the other and define the 2-norm of the result (||Δ||2).
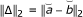 (vi)
(vi) -
6.
Any distinction at all between the coefficients would imply identifiability (i.e. if ||Δ||2 ≠ 0). In reality, the effect of assay error on parameter identification is inversely proportional to the magnitude of this distinction (and proportional to the magnitude of any assay error (ε)):
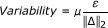 (1)
(1)


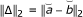
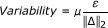
where: μ is a proportionality factor that incorporates factors such as the relative contribution of the parameter to the derivative of the relevant species concentration in the governing differential equation, and the absolute magnitude of the noise at the sampled times in relation to the relative magnitude of the parameter coefficient.
Thus, the method cannot accurately predict the coefficient of variation that a Monte Carlo analysis may find. However, it can predict the change of variation that might be observed when changes are made to the test sampling or stimulus protocols.
2.2 The dynamic insulin sensitivity and secretion test (DISST) model
2.2.1 Insulin pharmacokinetics
Initially, a validated model of insulin PKs [18, 19] is used to evaluate the method described, and is defined:


where: equation nomenclature is defined in Table 1
The model is used in the dynamic insulin sensitivity and secretion test (DISST) to define the PKs of insulin due to test stimulus [18, 20]. The model assumes that plasma insulin (I) is sampled. A traditional derivative based identifiability analysis of the model presented in Equations 2 and 3 using Ritt's pseudo-division algorithm [1, 21] is presented in Appendix 1.
2.2.2 Pharmaco-dynamics of glucose and insulin
The parameters of the glucose-insulin PDs can also offer insight into the identifiability of parameters. The DISST model of glucose-insulin PDs is defined [18, 19]:

where: equation nomenclature is defined in Table 2.
Although the structural identifiability of Equation 4 is trivial it is also presented in Appendix 1.
2.3 Participants
Parameter values from two participants of the pilot investigation of the DISST [18] are used to generate in-silico simulated data to construct and demonstrate the method proposed here. In-silico data is used in this analysis because it allows protocols to be changed to illustrate the impact on identifiability. The participant characteristics that are summarised in Table 3 represent the extremities of the range of cases encountered in typical research studies of insulin sensitivity.
2.4 Simulated test protocol
The simulated protocol is similar to the DISST test; a 10 g glucose bolus is administered at t = 7.5 and a 1 U insulin bolus at t = 17.5. The test duration is 60 minutes with a 5 minute sampling frequency. The U N profile is defined as a step function with three stages including basal, first and second phase production rates. The first phase of insulin production has a five-minute duration and begins with the glucose bolus. Simulations of plasma and interstitial insulin are completed using Equations 2 and 3, the parameter estimation equations from [22], n L and x L values from Table 3 and an a I value of 0.001 L/mU. Glucose is simulated using Equation 4 and the interstitial insulin profile obtained in the evaluation of Equations 2 and 3.
2.5 Iterative integral method
The analyses of this study will use the iterative integral method to identify parameters [20, 23]. Although the method has been presented [20], it is repeated in brief in Steps 1-5 below:
-
1.
The method converts the model governing equations to their integral formulation.
-
2.
The parameter coefficients and the remainder terms are evaluated between t = 0 and the sample times.
-
3.
The coefficients form the LHS of a matrix equation in terms of the parameters, while the remainder terms form the RHS. This matrix is evaluated to get parameter values.
-
4.
These parameter values are used to update the coefficient evaluations in step 2, which enables a more accurate matrix equation in step 3.
-
5.
Step 4 is iterated until convergence is achieved.
2.6 Analysis
A series of parameter and sampling scenarios were analysed using the models presented in a Monte Carlo analysis. Clinically measured physiological parameters of the NGT participant presented in Table 3 were used to define simulated responses to the test protocol described in Section 2.4. Samples were obtained from the simulated profiles at the defined times. Each iteration of the Monte Carlo analysis adds normally distributed assay error (the error magnitude is defined within each section). 100 iterations are used for each analysis with parameter identification by the iterative integral method. Only simulated profiles from the NGT participant are used until Section 3.2.2. Each scenario will present the mean value of those identified in the Monte Carlo simulation normalised by the simulation value from Table 3, and the coefficient of variation (CV) of each identified parameter (i.e. A mean of 1 and standard deviation of 0 implies perfect identification). The CV values are the paramount indicator of parameter trade-off during identification. The CV values are thus was compared to the ε/||Δ||2 value defined using the methods of Section 2.1 to obtained values for μ that linearise Equation 1.
2.7 Cases tested
A series of indicative cases will be investigated to show how the selection of model parameters, sample placement, participant behaviour and protocol dosing can have an effect on model identifiability.
-
The insulin pharmacodynamic model will include five variable parameters to be identified to confirm the robustness and convexity of the iterative integral method, and to confirm the findings of the traditional derivative-based identifiability analysis.
-
Parameter interference of n L and n K will be analysed. The nature of identifiability will be explored by alteration of the α I term that moderates the denominator of n L in Equation 2.
-
The effect of sample selection on parameter identification of n T and V P will be measured. (n T is the addition of n L and n K ).
-
The effects of sample omissions on SI and V G identification are measured.
-
The disparity of parameter identifiability in insulin resistant and sensitive individuals will be assessed using p G and SI as variable model parameters.
-
The protocol proposed in Section 2.4 will be altered to see if the identifiability of insulin resistant participants can be improved.
-
Measured samples that the proposed method claims are not valuable to stable identification are ignored and the identification process is repeated to confirm the prediction.
All cases will be tested with 1% and 3.5% normally distributed noise added to the virtually obtained data (to a maximum of 3 standard deviations).
3. Results
3.1 Analysis of the insulin pharmacokinetic model
3.1.1 Confirmation of global model identifiability
When the sampled data is used in the iterative integral method to define n L , n K , n I /V P , x L and V P as parameters, convergence to the simulation values occurs (Figure 1). This confirms the traditional identifiability analysis of Equations 2 and 3 in Appendix 1. However, when 1% normally distributed noise is added to the simulated data, parameter values do not converge to simulation values (Figure 1). When the sample noise is increased to 3.5%, which is more indicative of actual measurement noise encountered clinically, parameter convergence is significantly biased. Hence despite proven (no noise) structural identifiability, the addition of assay error or noise yields corrupted or potentially unidentifiable results.

Convergence of 5 parameter case. Mean absolute percentage error between the simulation and identified parameters in the presence of 0%, 1% and 3.5% random assay error, with respect to iterations of the iterative integral identification approach.
3.1.2 Hepatic and renal clearance rate identification
To understand why the addition of noise disables the identification, the case of interference between n K and n L is tested. In this analysis, all parameters of Equations 2 and 3 are set as constants and only n L and n K are identified as parameters. From the analyses in Appendix 1 and Section 3.1.1, parameter convergence is assured for the noiseless case. However, for the 1% and 3.5% noise cases parameter interference causes considerable parameter divergence in the value of the identified parameters compared to the actual values used in-silico. The Monte Carlo analysis described in Section 2.6 is used to evaluate these parameters in the presence of noise and the results are shown in Table 4.
The matrix equation used by the iterative integral method is a re-arrangement of Equation 2 and is in the form:

where: i= 5, 10, 15, ..., 60 minutes, matching sampling times.
Thus, the value of the ||Δ||2 term can be obtained for this model and sampling protocol as:

However, Table 4 shows that if a I is increased significantly to 0.05 L/mU, an arbitrarily chosen value that is not necessarily representative of physiology [24], parameter convergence is more stable. The ||Δ||2 term can be re-identified with the exaggerated α I value.

Thus, the parameters identified with the exaggerated α I term should have approximately 15 times smaller variability than those identified with the accepted α I value. Table 4 shows the effect of the α I distinction on the identified parameter values.
Table 4 shows the distinction between the effects of noise on identified parameters when the α I term is changed. Although the 0% noise case indicates that the parameters are uniquely identifiable, at 1% noise the variation in the identified values limits their clinical viability. At 3.5% noise, which may be expected in a real clinical setting, the parameters are no longer uniquely identifiable. This is illustrated by the very large CVs of the parameters. However, when the α I term is significantly increased, unique identifiability is once again possible, even with 3.5% noise. The mean ratio of variation caused by the disparate a I values was approximately 1:20. This is larger than the ratio predicted by the method (1:15), but still represents a positive outcome in terms of predicting the relative magnitude of the change.
The reason for this outcome can be observed in the increased contrast between integral formulations of the parameter coefficients. The contrast is shown graphically in Figure 2.

Renal and hepatic clearance coefficient integrals. The distinctions between the integral form of the hepatic and renal clearance coefficients when the standard (left) and exaggerated (right) α I values are used.
The difference between the curves at the sample times indicates the identifiability of the model parameters in this two-parameter case. Thus, when the saturation term is increased, the coefficients of the parameters are more distinct and identifiability is increased. Despite the positive findings of the typical identifiability analysis, a saturation value of 0.001 L/mU causes n K and n L to become uniquely un-identifiable in a real clinical setting. This outcome may be considered as an elementary finding that should be inferred with a quick observation of Equation 2. However, it points to a failing of typical a-priori identifiability tests that this approach can negate with a quick graphical analysis.
The findings of this analysis also show that the functional effects of n L and n K on insulin concentration in Equation 2 are so similar that there would be a negligible effect if the terms are combined. As such, further analysis of this model will use a combined n L and n K term (n T ) without the saturation term, which is negligible except at extremely high insulin concentrations. Equation 2 is thus redefined in Equation 5:

3.1.3 Plasma insulin distribution volume and insulin clearance identifiability
To identify n T and Vp the form of the governing matrix equation is:

where: 
As with the n K and n L analysis, the 0% noise case exactly reproduced the simulation values. Figure 3 shows the coefficients of the two parameters and three sampling protocols. In this case, Protocol 1 uses the 5 minutely sampling defined in Section 2.4. However, Protocol 2 uses samples at t = 0, 15, 20, and 60, and Protocol 3 uses samples at t = 0, 5, 45, and 60 minutes. Thus, Protocol 1 requires 13 samples while both protocol 2 and 3 only require four samples.

Plasma distribution volume and inuslin clearance coefficient integrals. Parameter coefficient distinctions using the three similar clinical protocols with distinct sampling regimens.
The ||Δ||2 terms can be defined for each of these protocols (Table 5) and the coefficients are displayed graphically in Figure 3.
The ||Δ||2 values indicate that Protocol 3 will be comparatively unable to reproduce the simulation values. Contrary to the expected result that parameter identification is best with frequently sampled Protocol 1, the method predicts that the sparsely sampled Protocol 2 will be slightly more accurate.
Table 6 shows the parameter convergence and variability for the exact same model with the three different sampling protocols.
It is evident that although Protocols 2 and 3 contain the same number of samples, the resolution of the identified parameters is considerably reduced in Protocol 3. In effect,  was un-identifiable with Protocol 3. This result occurs because of the lack of distinction in the coefficients of the parameters at the sample times as indicated in Table 5 and Figure 3.
was un-identifiable with Protocol 3. This result occurs because of the lack of distinction in the coefficients of the parameters at the sample times as indicated in Table 5 and Figure 3.
Thus, the method predicted the poor performance of the third protocol while it predicted much lower variability for both Protocols 1 and 2. However, it also suggests that Protocol 2 would improve slightly upon Protocol 1, which was not the case as both protocols performed equally in terms of parameter identifiability. It is expected that it's equality of variance is an artefact of the normalisation as a function of mean coefficient at the sample value, artificially lowering the magnitude of the ||Δ||2 terms in Protocol 1.
Overall, these findings highlight the inefficiency, extreme clinical burden and intensity of frequent sampling in contrast to well-positioned and infrequent sample timing. More specifically, Protocol 1 used 9 more samples than Protocol 2 with significant added clinical intensity and assay cost (~200% more!) for absolutely no information gain. This outcome was successfully predicted by the identifiability analysis method presented.
3.2 Analysis of the glucose PD model
Equation 4 will be used in the analysis of identifiability of terms frequently used to model the PDs of insulin and glucose. All analyses in this section will simulate insulin concentration profiles for the plasma and interstitium only once for each Monte Carlo analysis. Thus for clarity and simplicity, it is assumed that insulin is not subject to assay error here. Furthermore, while glucose assay error from a blood gas analyser is approximately 2%, errors of 1% and 3.5% will be used for consistency with Section 3.1. As such, the resultant coefficients of variation should not be considered fully applicable clinically, but merely as an indication of parameter trade-off during identification. The Monte Carlo analysis method with the NGT participant described in Section 2.3 is repeated for the glucose PD model. The IGT participant will be used in tandem with the NGT participant from Section 3.2.2.
3.2.1 Insulin sensitivity and distribution volume
Use of the DISST model typically entails the identification of SI and V G in Equation 4 [18, 20, 25]. As such, this case is tested using the proposed method and three potential sampling protocols. Specifically, Protocol 1 uses the 5-minute sampling resolution described in Section 2.4, while Protocols 2 and 3 use 10 and 20-minute resolutions, respectively. Figure 4 and Table 7 indicate that these parameters are uniquely identifiable in the presence of measurement noise given a surprisingly small number of data points.

Insulin sensitivity and glucose distribution volume coefficient integrals. Distinction between the integral of the coefficients of the parameters of Equation 5 when differing sampling resolutions are used.
Table 7 shows that parameter stability is generally very high even in a sparsely sampled data set with a relatively high level of noise. This result was expected due to the relatively large difference in the coefficient integrals shown in Figure 4 for each of the sampling protocols. Thus, like the case of V P and n T , intelligent sample timing can significantly reduce clinical burden and study cost with negligible loss of information. Furthermore, the proposed method successfully predicted this outcome.
3.2.2 Insulin sensitivity and glucose dependent decay
Model-based studies of insulin sensitivity frequently identify a parameter synonymous with p G in addition to SI and V G as parameters when using the Minimal Model [10] or similar. However, although these parameters are mathematically distinct, they are known to trade-off during identification and practical identifiability is not generally assured. It has been reported that these issues can be exacerbated for insulin resistant (IR) individuals [7, 8]. Thus, the second, IGT participant defined in Table 3 will also be analysed.
Some insight into the parameter trade-off during identification of dynamic test data can be seen in Figure 5 that contrasts the integral formulations of the parameter coefficients based on glucose tolerance status. The contrasting shape of the integral formulations of the parameter coefficients is best observed in the p G coefficient. The p G coefficient is the only term in Equation 4 that could possibly become negative. Thus, the integral of the coefficient can form a convex shape that contrasts well with the coefficient of SI as seen for the NGT participant in Figure 5. However, the negative coefficient of p G can only occur when the participant's glucose concentration goes below the basal concentration. Thus, as only NGT participants achieve such concentration reductions in typical dynamic insulin sensitivity tests, the parameter identifiability of IR participants is impaired in comparison. In particular, Figure 5 (right) shows minimal difference and a much smaller ||Δ||2 value for this IR individual indicating increasing potential for parameter trade-off in the identification process and loss of effective identifiability. This is despite an identical test protocol and model.

Insulin sensitivity and glucose dependent uptake in NGT and IR individuals. The disparity between normo-glucose tolerant and insulin resistant individuals in terms of the distinction of the integral formulations of the coefficients of SI and p G .
As mentioned, this limitation of the Minimal Model has been reported, but not explained in the literature until now.
Table 8 shows the parameter error when the 60 minute 10-minute sampling protocol is used.
It is apparent that the insulin resistant individual's parameter identifiability is much lower than the NGT participant despite the identical PD model, test protocol and identification process. Table 8 highlights this result, as well as the increasing loss of identifiability as assay error increases. This is in accordance to published findings and the proposed method's prediction.
3.2.3 A hypothetical protocol to enable pG identification in dynamic tests
To forcibly remove this ambiguity introduced by the comparable coefficients of the IR individual, the protocol of the DISST could be altered. After an initial observation of the effect of the insulin bolus on glucose concentration, more insulin could be introduced to ensure that the participant's glucose concentration is maintained approximately 0.5 mmol/L below the basal concentration. Such a protocol may include an extension of the protocol described in Section 2.4 wherein a period of slight hypoglycaemia is achieved for each participant with a series of participant-specific insulin boluses administered with feed-back control.
To allow a fair comparison between the variability of the parameters of the proposed protocol and the protocol used in Section 3.2.2 the sampling regimen and test duration will be maintained. Thus, the additional insulin is administered as a bolus t = 32.5 minutes. In a clinical setting, the magnitude of the bolus would be participant-specific and dependent on the glucose concentration response alone (as glucose can be assayed in real-time). Note that this task would be very difficult and potentially dangerous in a regular clinical setting. In particular, the amount of insulin required would vary between participants, and must be estimated in ignorance of endogenous insulin production. This may cause a high incidence of potentially harmful hypoglycaemia. This protocol is only mooted to illustrate the ability of the method, and in reality the introduction of additional insulin could be applied slowly and safety would be assured.
For the case of the IR participant presented here, reducing glucose sufficiently would require a 3U bolus at t = 32.5 minutes.
The proposed protocol would alter the shapes of the integral of the parameter coefficients for the resistant individual. In doing so, it is hypothesised that it would increase the distinction between these curves to avoid the similarity seen in Figure 5 (right) to ensure identifiability. The ||Δ||2 value obtained for the IGT participant and the updated protocol indicates a reduction in variability ratio of approximately 1:2.2. Figure 6 contrasts with Figure 5 (right) as it shows how the added bolus significantly increases the distinction between the coefficients of the identified parameters. Table 9 shows the outcomes of this analysis.

Effect of an alternative protocol to maximise parameter distinction in IR individuals. The effect of the added insulin bolus on the distinction of the coefficient integrals of p G and SI for the IR participant.
Although the inhibitive CV values for the parameters indicate that the proposed protocol could not be used clinically, the variability decreased in the order predicted by the identifiability method presented. The hypothetical protocol presented has confirmed the reasons discussed for the poor parameter identification observed in many clinical studies which utilise these two competing parameters [7, 8]. Furthermore, it demonstrates a limitation of traditional identifiability methods, which provide an evaluation of identifiability in ignorance of probable participant behaviour or test protocol design.
The protocol presented would be virtually impossible to apply clinically in the 60 minute duration as it is shown here. However, this analysis was limited by the need for a comparable duration and sampling regimen to Section 3.2.2. The method could thus be used to define similar protocols that could yield data that enables unique identification of these parameters. If such protocols are pursued, they would most likely require two sections in a much longer test. The first section would involve the protocol defined in Section 2.4, and would be followed immediately by an infusion of insulin designed to safely bring the participant's glucose concentration to 0.5 mmol/L below the basal level. Robust results would be most assured if the participant's glucose concentration was maintained below this level for approximately 30 minutes, and thus, the protocol would most likely require about 2 hours. However, a stable result both in terms of SI and p G would be generally assured.
3.2.4 Removal of redundant points
The t = 40 minute sample in Figure 5 (left) and t = 30 in Figure 5 (right) show virtually no distinction between the coefficients of either profile. Thus, according to the theory presented, it should provide no value to the identification process. To test this, the analysis of Section 3.2.2 is repeated with these samples removed. Figure 7 shows how the omitted data point do not significantly alter the distinction shown in Figure 5 (Section 3.2.2). Table 10 shows how the identified parameters were affected by the omission of data that the method implied were redundant.

Effect of omitting assumed negligible samples. The coefficient comparison in alternative sampling protocols that omit the samples that according to Figure 5 have almost negligible value in terms of identifiability due to the very small magnitude of distinction at the sample times.
The findings of this analysis imply that the omission of the samples that were assumed to be obsolete had little effect on the outcome of the identification process. Most changes were very small and only those for the particularly un-stable parameters showed any significant changes.
3.3 The value of μ
The value of μ in Equation 1 can be used to enable prediction of the probable variability in the identified parameters in a Monte Carlo simulation. Thus, the effects of protocol changes on the parameter identifiability can be predicted without the need for numerous Monte Carlo simulations. To identify the value of μ linear relationships between the CV values obtained and the ε/||Δ||2 values are defined. As noiseless identifiability of all models has been proven, the y-intercept can be assumed at zero, and μ can be identified using Equation 6:

Figure 8 shows the adherence of μ to linear relationships while Table 11 shows the value of μ for the different parameters.

Linear regression of μ. Comparisons between CV values and ε/||Δ||2 terms to provide parameter specific values for μ.
Table 11 presents the μ values identified by the gradients of the regression lines
It can be observed that no single value for μ can be applied across all models and that different parameters are considerably more susceptible to the distinction of the parameter coefficients. However, the general adherence to the linear relationships observed in most examples implies that the form of Equation 1 is accurate for this purpose with the possible exception of SI in Sections 3.2.2 and 3.2.4.
4. Conclusions
The method presented was able to predict and explain the parameter identifiability behaviour exhibited in models of insulin kinetics and insulin/glucose dynamics. This capability is in direct contrast to the traditional derivative-based identifiability analysis [1, 3, 11–13] that can only provide a confirmation of an infinitesimal distinction of the parameters in the governing equations. In addition to the ability to predict parameter identifiability, the method has been shown to be able to aid sample selection and explain the non-identifiability of the p G term in common insulin sensitivity tests for IR participants of dynamic tests. It was also used to derive and justify a novel protocol to make this parameter more identifiable in this subgroup. Furthermore, the method also accurately predicted sample redundancy.
Like the proposed method, the method proposed by Raue et al. [4] recognises the ability of apparently identifiable parameters to become practically non-identifiable in the presence of assay error and discrete sampling. The Raue et al. method requires numerous simulations and parameter identification processes to characterise the model sensitivity to variations in each model parameter. In contrast, the proposed method allows a quick graphical analysis, which can produce immediately apparent and intuitive results. Furthermore, the proposed method can quickly appraise protocol variants, and provide indications of the reason for practical non-identifiability. The method of Raue et al. is a more general method as it can appraise most model configurations, whereas the proposed method is currently limited to models with two separable parameters.
In reality, many models utilise more than two parameters to describe physiological kinetics and seek to identify all at once. It is expected that development of the proposed method will enable identifiability analyses of such models. However, more care must be taken to construct the coefficient integral formulations as combinations of parameters that may come into conflict. This task would require the contrast between the most deleterious combinations of integral coefficients to be measured. However, this point was not explored in this study, as the goal was to introduce the overall approach.
Only cases with separable parameters in terms of measured species were analysed. In reality, some model parameters are intrinsically linked and this method will not work. An example of linked parameters would be insulin sensitivity and insulin effect saturation that requires a Michaelis-Menten formulation. In addition, some parameters effect remote, un-measured concentrations or masses and are thus not able to be identified with this method. For example, the n C term in Equation 3 could not be evaluated for identifiability using this method without the inclusion of measurements of interstitial insulin [26]. As such, this method should not replace the traditional identifiability analysis, but be used in tandem with it (or methods such as Raue et al. [4] or similar) to produce both theoretical and practical investigations of identifiability.
Furthermore, the model assumes that an expected range of parameter values is known prior to the commencement of the clinical study. This knowledge is important, as the method requires that species simulations are available to define the coefficients of the parameters. However, in most cases, the researcher will be able to obtain an indication of the likely range of parameter values in a cohort from a brief literature search, and likely test outcomes could be cases that can be safely evaluated prior to clinical testing.
There is also an assumption that the model captures all of the dynamics of the system perfectly. In reality no model can provide such accuracy. In particular, Figures 4, 5, 6, 7 show a sample taken at t = 10 for glucose. In reality, this sample will be affected heavily by error caused by incomplete mixing, and although the method presented indicates that this is a valuable sample, if it is used in the glucose pharmacodynamic model of Equation 5, the resultant parameters will be overly influenced by an un-modelled mixing effect.
Although the method has limitations and potential for improvement, it can provide valuable information at a study design stage, as well as valuable identifiability information not available from typical methods. It can differentiate between the applicability of different dynamic tests based on cohorts, and also help to define optimal sample timing and frequency. In particular, it explained the observation of poor parameter convergence in the Minimal Model for insulin resistant participants that has been widely reported but without clearly defining the cause. Thus, despite the method's limitations, it should still be used in the design stage of a study to ensure that the resultant clinical data can provide usable results, and time and money is not wasted.
Finally, the method has highlighted the limitation of discrete binary identifiability analyses as providing potentially misleading assurances of parameter identifiability in real clinical applications, and shown that identifiability is instead a continuous artefact of sample timing and the distinction between parameter coefficients.
Appendix 1: Structural identifiability
A1.1 Structural identifiability of the insulin model
Using the method of algebraic derivative approach of [21] and refined in [1] the identifiability of the model can be confirmed. Using the ranking:

generates the characteristic set of Equations 2 and 3.


if: Y = I
Thus, the following coefficients can be defined:




Using arbitrary values for the coefficients confirms global identifiability of the insulin kinetic model of Equations 2 and 3.
A1.2 Structural identifiability of the glucose model
The structural identifiability of the glucose model is considerably less complex than the insulin kinetic model. In particular, the characteristic set is defined:

and thus the coefficients are defined:


and observation confirms that p G , SI, G b and V G are globally identifiable using derivative-based identifiability analysis.
References
Bellu G, Saccomani MP, Audoly S, D'Angio L: DAISY: A new software tool to test global identifiability of biological and physiological systems. Comput Methods Programs Biomed 2007, 88: 52–61. 10.1016/j.cmpb.2007.07.002
Bellman R, Åström KJ: On structural identifiability. Mathematical Biosciences 1970, 7: 329–339. 10.1016/0025-5564(70)90132-X
Pohjanpalo H: System identifiability based on the power series expansion of the solution. Mathematical Biosciences 1978, 41: 21–33. 10.1016/0025-5564(78)90063-9
Raue A, Kreutz C, Maiwald T, Bachmann J, Schilling M, Klingmüller U, Timmer J: Structural and practical identifiability analysis of partially observed dynamical models by exploiting the profile likelihood. Bioinformatics 2009, 25: 1923–1929. 10.1093/bioinformatics/btp358
Schaber J, Klipp E: Model-based inference of biochemical parameters and dynamic properties of microbial signal transduction networks. Current Opinion in Biotechnology 2011, 22: 109–116. 10.1016/j.copbio.2010.09.014
Erichsen L, Agbaje OF, Luzio SD, Owens DR, Hovorka R: Population and individual minimal modeling of the frequently sampled insulin-modified intravenous glucose tolerance test. Metabolism 2004, 53: 1349–1354. 10.1016/j.metabol.2004.04.011
Pillonetto G, Sparacino G, Magni P, Bellazzi R, Cobelli C: Minimal model S(I) = 0 problem in NIDDM subjects: nonzero Bayesian estimates with credible confidence intervals. Am J Physiol Endocrinol Metab 2002, 282: E564–573.
Quon MJ, Cochran C, Taylor SI, Eastman RC: Non-insulin-mediated glucose disappearance in subjects with IDDM. Discordance between experimental results and minimal model analysis. Diabetes 1994, 43: 890–896. 10.2337/diabetes.43.7.890
Caumo A, Vicini P, Zachwieja JJ, Avogaro A, Yarasheski K, Bier DM, Cobelli C: Undermodeling affects minimal model indexes: insights from a two-compartment model. Am J Physiol 1999, 276: E1171–1193.
Bergman RN, Ider YZ, Bowden CR, Cobelli C: Quantitative estimation of insulin sensitivity. Am J Physiol 1979, 236: E667–677.
Audoly S, Bellu G, D'Angio L, Saccomani MP, Cobelli C: Global identifiability of nonlinear models of biological systems. IEEE Trans Biomed Eng 2001, 48: 55–65. 10.1109/10.900248
Audoly S, D'Angio L, Saccomani MP, Cobelli C: Global identifiability of linear compartmental models: a computer algebra algorythm. IEEE Trans Biomed Eng 1998, 45: 36–47. 10.1109/10.650350
Chin SV, Chappell MJ: Structural identifiability and indistinguishability analyses of the Minimal Model and a Euglycemic Hyperinsulinemic Clamp model for glucose-insulin dynamics. Computer Methods and Programs in Biomedicine 2010, in press. Corrected Proof
McDonald C, Dunaif A, Finegood DT: Minimal-model estimates of insulin sensitivity are insensitive to errors in glucose effectiveness. J Clin Endocrinol Metab 2000, 85: 2504–2508. 10.1210/jc.85.7.2504
Pillonetto G, Sparacino G, Cobelli C: Numerical non-identifiability regions of the minimal model of glucose kinetics: superiority of Bayesian estimation. Math Biosci 2003, 184: 53–67. 10.1016/S0025-5564(03)00044-0
Cobelli C, Caumo A, Omenetto M: Minimal model SG overestimation and SI underestimation: improved accuracy by a Bayesian two-compartment model. Am J Physiol 1999, 277: E481–488.
Denti P, Bertoldo A, Vicini P, Cobelli C: Nonlinear mixed effects to improve glucose minimal model parameter estimation: A simulation study in intensive and sparse sampling. IEEE Trans Biomed Eng 2009, 56: 2156–2166.
Lotz TF, Chase JG, McAuley KA, Shaw GM, Docherty PD, Berkeley JE, Williams SM, Hann CE, Mann JI: Design and clinical pilot testing of the model based Dynamic insulin sensitivity and secretion test (DISST). J diabetes Sci Technol 2010, 4: 1195–1201.
Lotz T, Chase JG, Lin J, Wong XW, Hann CE, McAuley KA, Andreassen S: Integral-Based Identification of a Physiological Insulin and Glucose Model on Euglycaemic Clamp Trials. 14th IFAC Symposium on System Identification (SYSID 2006); March 29–31; Newcastle, Australia. IFAC 2006, 0000: 6-pages.
Docherty PD, Chase JG, Lotz T, Hann CE, Shaw GM, Berkeley JE, Mann JI, McAuley KA: DISTq: An iterative analysis of glucose data for low-cost real-time and accurate estimation of insulin sensitivity. Open Med Inform J 2009, 3: 65–76. 10.2174/1874431100903010065
Ritt JF: Differential Algebra. Providence, RI: Amer. Math. Soc; 1950.
Van Cauter E, Mestrez F, Sturis J, Polonsky KS: Estimation of insulin secretion rates from C- peptide levels. Comparison of individual and standard kinetic parameters for C-peptide clearance. Diabetes 1992, 41: 368–377. 10.2337/diabetes.41.3.368
Hann CE, Chase JG, Lin J, Lotz T, Doran CV, Shaw GM: Integral-based parameter identification for long-term dynamic verification of a glucose-insulin system model. Comput Methods Programs Biomed 2005, 77: 259–270. 10.1016/j.cmpb.2004.10.006
Thorsteinsson B: Kinetic models for insulin disappearance from plasma in man. Dan Med Bull 1990, 37: 143–153.
Lotz T, Chase JG, McAuley KA, Shaw GM, Wong J, Lin J, Le Compte AJ, Hann CE, Mann JI: Monte Carlo analysis of a new model-based method for insulin sensitivity testing. Computer Methods and Programs in Biomedicine 2008, 89: 215–225. 10.1016/j.cmpb.2007.03.007
Sjostrand M, Holmang A, Lonnroth P: Measurement of interstitial insulin in human muscle. Am J Physiol 1999, 276: E151–154.
Acknowledgements
The authors would like to thank Professor Jim Mann and Dr Kirsten McAuley of the Edgar National Centre for Diabetes Research who organised the clinical investigation that allowed this research. This project was funded by the Health Research Council of New Zealand (HRC) and the Foundation for Research, Science and Technology (FRST).
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors' contributions
PDD contributed to the development of the concept, investigation design, interpretation of results, and drafted the manuscript. JGC and TD refined the analysis and interpretation, and edited the manuscript. TFL contributed to the investigation design, interpretation of results, and edited the manuscript. All authors have read and approved the final manuscript.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
This article is published under license to BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Docherty, P.D., Chase, J.G., Lotz, T.F. et al. A graphical method for practical and informative identifiability analyses of physiological models: A case study of insulin kinetics and sensitivity. BioMed Eng OnLine 10, 39 (2011). https://doi.org/10.1186/1475-925X-10-39
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1475-925X-10-39