- Research
- Open access
- Published:
Image reconstruction of fluorescent molecular tomography based on the tree structured Schur complement decomposition
BioMedical Engineering OnLine volume 9, Article number: 20 (2010)
Abstract
Background
The inverse problem of fluorescent molecular tomography (FMT) often involves complex large-scale matrix operations, which may lead to unacceptable computational errors and complexity. In this research, a tree structured Schur complement decomposition strategy is proposed to accelerate the reconstruction process and reduce the computational complexity. Additionally, an adaptive regularization scheme is developed to improve the ill-posedness of the inverse problem.
Methods
The global system is decomposed level by level with the Schur complement system along two paths in the tree structure. The resultant subsystems are solved in combination with the biconjugate gradient method. The mesh for the inverse problem is generated incorporating the prior information. During the reconstruction, the regularization parameters are adaptive not only to the spatial variations but also to the variations of the objective function to tackle the ill-posed nature of the inverse problem.
Results
Simulation results demonstrate that the strategy of the tree structured Schur complement decomposition obviously outperforms the previous methods, such as the conventional Conjugate-Gradient (CG) and the Schur CG methods, in both reconstruction accuracy and speed. As compared with the Tikhonov regularization method, the adaptive regularization scheme can significantly improve ill-posedness of the inverse problem.
Conclusions
The methods proposed in this paper can significantly improve the reconstructed image quality of FMT and accelerate the reconstruction process.
Background
Near-infrared (NIR) light can travel several centimeters through biological tissue, and hence has the potential to qualify the molecular information by fluorochromes in tissue [1]. Recently, there has been increasing interest in the molecularly-based medical imaging method, such as fluorescent molecular tomography (FMT) [2–4], in which the injected fluorophore may accumulate in diseased tissue. During the imaging process, the tissue surface is illuminated with excitation light. Then, the fluorophores are excited to emit the light, which is detected as fluorescence [5]. The process of fluorescent light generation and transportation through tissues can be described by a forward model, so that the surface measurements can be predicted on the basis of a guess of the system parameters and the given source positions. To reconstruct an image, it is necessary to calculate the internal optical and fluorescent properties with the given measured data and sources [6].
One of the major challenges in the reconstruction of FMT is its high computational complexity resulted from extremely large-scale matrix manipulations. Generally, the iterative solution approaches, such as CG method [7] and Gauss-Newton (GN) method [8], are more efficient than the direct solution approaches. Additionally, the iterative methods based on the reduced system can be more efficient than those based on the global system. One of such systems is the Schur complement system, which was firstly used by Haynsworth [9]. The condition number of the Schur complement of a matrix is never greater than that of the given matrix, and hence the convergence properties of iterative solving of linear systems can be significantly improved [7, 10]. In this paper, we propose to adapt this idea for the FMT reconstruction. The most important innovation of our method lies in its tree structured level-by-level decomposition strategy, where decompositions in each level are performed in two ways. This strategy is quite different from that in [10] where only one component of the global solution is derived in the Schur complement system. The advantages of our method are obvious because a further improvement in the reconstruction accuracy and speed can be achieved with level-by-level Schur complement decomposition. Another contribution of this paper is that we propose a modified spatially variant regularization method incorporating the objective function to tackle the ill-posed nature of the inverse problem.
Methods
Forward Model and Finite Element Formulation
FMT acquisitions are obtained through a two-step image formation model [11]. In the first step, sources at several locations are used to illuminate the tissue. This step, in frequency domain, is driven by the diffusion equation [12]

where the subscript x denotes the excitation wavelength; ∇ is the gradient operator; S x (W/cm3) is the excitation light source; Φ x (W/cm2), D x (cm), and k x (cm-1) represent the photon fluence, the diffusion coefficient, and the decay coefficient, respectively; Ω denotes the bounded domain of reconstruction.
In the second step, the fluorophores are excited to emit the fluorescence. The second step can be modelled by a second diffusion equation

where the subscript m indicates the emission wavelength, ω(rad/s) denotes the modulation frequency of the source. S m is the emission light source. The diffusion coefficient D x,m (cm), and the decay coefficient k x,m (cm-1) are defined, respectively, as[6]


where μ
ax,mi
(cm-1) denotes the absorption coefficient due to endogenous chromophores; μ
ax,mf
(cm-1) represents the absorption coefficient due to exogenous fluorophores;  is the reduced scattering coefficient; q is the quantum efficiency of the fluorophore; τ(s) is the lifetime of fluorescence; and finally, c(cm/s) is the speed of light in the medium.
is the reduced scattering coefficient; q is the quantum efficiency of the fluorophore; τ(s) is the lifetime of fluorescence; and finally, c(cm/s) is the speed of light in the medium.
Here, the Robin-type boundary conditions are implemented on the boundary ∂Ω of domain Ω to solve the above diffusion equations


where n is a vector normal to the boundary ∂Ω, b x,m is the Robin boundary coefficient.
To solve the forward problem within the finite element method (FEM) framework, the domain Ω is divided into P elements and joined at N vertex nodes. The solution Φ
x,m
is approximated by the piecewise linear function  , with φ
i
(i = 1...N) being basis functions [13]. Hence, equations (1) and (2) can be rewritten as
, with φ
i
(i = 1...N) being basis functions [13]. Hence, equations (1) and (2) can be rewritten as


where


The elements of finite element matrix A x,m can be obtained from the formula

with Ω h and Γ h being the bounded domain and its boundary, respectively.
Inverse Process of FMT
The inverse process of FMT is to estimate the spatial distribution of the optical or fluorescent properties of the tissues from measurements [14]. In the discrete case, the reconstruction problem can be defined as the optimization of the objective function

where G is the forward operator, || || is L2-norm, x and y are the calculated optical or fluorescent properties of the tissues and the detector readings, respectively.
Suppose that the objective function E attains its extremum at x + Δ x, expanding the gradient of the objective function E' about x in a Taylor series and keeping up to the first-order term leads to

Equation (13) can be further written as [15]

where T denotes the transpose, Δ y = y - G(x) is the residual data between the measurements and the predicted data. The Jacobian matrix J is a measure of the rate of change in measurement with respect to the optical parameters. It describes the influence of a voxel on a detector reading. H is the Hessian matrix, whose entries are the second-order partial derivatives of the function with respect to all unknown parameters describing the local curvature of the function with respect to many variables [16].
Introducing the Tikhonov regularization term to tackle the ill-posedness of the inverse problem and ignoring the Hessian matrix, the solution to the linearized reconstruction problem can be described as follows

where λ is a regularization parameter, which can be determined by the Morozov discrepancy principle [17], I is an identity matrix.
Adaptive Regularization Scheme
The problem of image reconstruction for FMT is ill-posed [18]. The Tikhonov regularization technique, as mentioned above, is one of the major methods to reduce the ill-posedness of the problem [19]. However, there exists one protrudent difficulty for this technique in the determination of the regularization parameter. A general unexpected characteristic of the NIR imaging is that the resolution and contrast of the reconstructed images degrade with the increased distance from the sources and the detectors [20]. Considering the fact that the value of the regularization parameter has important effect on the contrast and resolution of the resultant images, one strategy to solve this problem is to use a spatially variant regularization parameter. Meanwhile, it can be inferred that the objective function is related to the regularization parameters [15]. During the process of minimizing the objective function, decreasing λ will speed up the convergence if the value of objective function is decreasing, otherwise increasing λ can enlarge the searching area (trust-region). Upon the basis of these considerations, we propose a modified regularization method both adaptive to the spatial variations and the objective function.
Suppose that the number of measurements and the number of the vertex nodes are M and N, respectively. Thus, we have for the matrices in equation (15): Δ x∈RN × 1, Δ y∈RM × 1, J∈RM × N, and I∈RN × N. To construct a spatially variant regularization framework, the inverse term of (JT J + λ I)-1 in equation (15) is replaced with (JT J + λ)-1, which results in the following equation

where  is a diagonal matrix. Equation (16) can be rewritten as
is a diagonal matrix. Equation (16) can be rewritten as

with Δ x i (i = 1, 2, ..., N) being the component of the vector Δ x. It can be easily seen that each node p i (i = 1, 2,...,N) in the reconstructed domain is regularized by a corresponding regularization parameter λ i (i = 1, 2,...,N) respectively. Obviously, the above mentioned Tikhonov regularization can be regarded as a special case of equation (17) when λ 1 = λ 2 = ⋯λ N = λ.
It was pointed out in [21] that, the resolution and contrast of the images decrease with the increment of the regularization parameters and vice versa. Therefore, the adaptive regularization parameter λ i can be defined as follows to compensate the decrease of the resolution and contrast with the increased distance from the sources and detectors:

where r i is the position of node p i , r s and r m respectively denote the positions of the source and detector closest to the node p i , c 1 and c 2 are two positive parameters determined empirically in our paper.
To make the regularization parameter adaptive to the objective function as defined in equation (12), we propose to incorporate it in the regularization as follows

In equation (19), the arctan function is used to guarantee a relatively small fluctuation range of the regularization parameters and avoid too large values of them. Obviously, regularization parameters determined from equation (19) relate to the objective function in a similar manner to that as pointed out before. In such a way, the regularization parameters are adaptive not only to the spatial variations but also to the variations of the objective function to accelerate the convergence.
Reconstruction Based on the Schur Complement System
As has been pointed out previously, the iterative methods based on the Schur complement system can be more efficient to solve large-scale problems. Hence, we propose to reconstruct the tomographic image of FMT with level-by-level decomposition in the Schur complement system.
For convenience of discussions, equation (16) can be further rewritten in a more compact form as

where k = JT J + λ and b = JT Δ y.
To solve the inverse problem of FMT in the Schur complement system, the solution space Rnis firstly decomposed into two subspaces of U and V with dimensions m and n-m, respectively. Let [Γ Ψ] be an orthonormal basis of the solution space Rn. The basis of the m-dimensional coarse subspace U is formed by the columns of Γ ∈ Rn × mand the columns of Ψ ∈ Rn×(n-m)form the basis of the (n - m) dimensional subspace V.
Therefore, the solution to equation (20) can be expressed with the bases of the two subspaces as follows

where u and v are the projections of Δ x on the subspaces U and V, respectively.
Because both the condition number and the scale of the system can be reduced after Schur complement decomposition, we propose to further decompose both the projections u and v level by level with the Schur complement decomposition along two paths in a tree structure, and then solve the subsystems in the Schur complement systems. Our approach is different from that proposed in [10], where only the projection v is solved in the Schur complement system. The level-by-level Schur complement decomposition can be schematically illustrated as in Figure 1. We derive the iterative system in the following discussions.

Schematic illustration of Schur complement decomposition with a tree structure. The global solution Δ x is decomposed with the Schur complement system level by level along the two paths in the tree structure.
Suppose that the subsystem at the i th level is as follows

where S (i, j) is the Schur complement matrix with the subscript (i, j) being the j th (j = 0, 1,..., 2i) term at the i th (i = 0, 1,..., L) level in the tree structure as illustrated in Figure 1. Particularly, S (0,0) is the global matrix k as defined in equation (20). To solve this system in the Schur complement system, equation (22) will be further decomposed at the i+1th level. Thus, the solution Δ x (i,j) is firstly expressed with the bases of the two subspaces as

where Δ x (i+1,2j-1) and Δ x (i+1,2j) are the projections of Δ x (i,j) on the subspaces formed by the columns of Γ (i,j) and Ψ (i,j), respectively.
Substituting equation (23) into equation (22) yields

Multiplying both sides of equation (24) from the left by [Γ (i,j) Ψ (i,j)]T, we can obtain

Thus, equation (25) can be further rewritten into a two-by-two block system

where  ,
,  ,
,  , and
, and  , while the two components on the right-hand side (RHS) of equation (26) are
, while the two components on the right-hand side (RHS) of equation (26) are  , and
, and  . From equation (26), it can be seen that S
(i,j)11 and S
(i,j)22 correspond to the equations for the unknowns of Δ x
(i+1,2j-1) and Δ x
(i+1,2j), respectively, while S
(i,j)12 and S
(i,j)21 define the coupling between these two sets, which will be eliminated in the following discussions.
. From equation (26), it can be seen that S
(i,j)11 and S
(i,j)22 correspond to the equations for the unknowns of Δ x
(i+1,2j-1) and Δ x
(i+1,2j), respectively, while S
(i,j)12 and S
(i,j)21 define the coupling between these two sets, which will be eliminated in the following discussions.
Applying block Gaussian elimination to equation (26) leads to [22]

where  , which is called the Schur complement with respect to S
(i,j)11
[7],
, which is called the Schur complement with respect to S
(i,j)11
[7],  . From equation (27), we have
. From equation (27), we have


It can be found that the condition number of matrix S (i+1,2j) is smaller than that of matrix S (i,j) [9]. Hence, solving the inverse problem in the Schur complement system at the i+1th level will be more efficient than solving it at the i th level. We herein solve equation (29) using the biconjugate gradient method [23]. Its advantage is that it does not square the condition number of the original equations [24]. Basically, the biconjugate gradient method can be used to solve the large-scale systems with the fastest speed among all the generalized conjugate gradient methods in many cases [25]. The algorithm for solving equation (29) can be summarized as follows
Algorithm 1
-
1.
Input an initial guess Δ x (i+1,2j)0;
-
2.
Initialize d 0 = f 0 = r 0 = p 0 ← b (i+1,2j) - S (i+1,2j) Δ x (i+1,2j)0;
-
3.
For k = 0, 1, 2... until convergence do
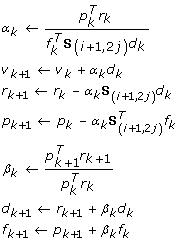
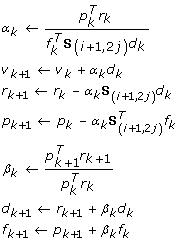
End for
After the derivation of Δ x (i+1,2j) from equation (29) with algorithm 1, the next task is to obtain the other component of Δ x (i+1,2j-1) for the synthesis of the solution Δ x (i,j). Here, Δ x (i+1,2j-1) is also solved in the Schur complement system due to its low condition number.
Eliminating the block S (i,j)12 in equation (26) using block Gaussian elimination with S (i,j)22 as pivot block, we have

where  and
and  . Thus S
(i+1,2j-1) is the Schur complement with respect to S
(i,j)22.
. Thus S
(i+1,2j-1) is the Schur complement with respect to S
(i,j)22.
From equation (30), we can obtain

Thus, the solution Δ x (i+1,2j-1) can be obtained in a same manner as in Algorithm 1, and the only difference is that Δ x (i+1,2j), S (i+1,2j), and b (i+1,2j) should be replaced with Δ x (i+1,2j-1), S (i+1,2j-1), and b (i+1,2j-1), respectively. Solving equation (31) is computationally efficient because of the reduced condition number in the Schur complement system [7]. Moreover, such a strategy of deriving both Δ x (i+1,2j-1) and Δ x (i+1,2j) in the Schur complement system can be implemented in a parallel manner, since equations (29) and (31) are decoupled. Therefore the subsystem at the i th level as in equation (22) can be decomposed into the two linear subsystems at the i+1th level, i.e., Schur complement systems as in equations (29) and (31). After obtaining Δ x (i+1,2j-1) and Δ x (i+1,2j), they are then substituted into equation (23) to yield the solution Δ x (i,j) at the i th level. The whole reconstruction algorithm is summarized as follows
Algorithm 2
-
1.
Set x 0 to an initial guess;
-
2.
x ← x 0, calculate b and k at x in equation (20) with the adaptive regularization scheme as in equation (19);
-
3.
The global system of equation (20) is decomposed with the Schur complement system level by level in a same manner as the decomposition of equation (22) into equations (29) and (31) to obtain the subsystem S (i,j) Δ x (i,j) = b (i,j) at the i th level for i =1,..., L and j =1,..., 2i, the subspaces at the i th level are formed by the columns of Γ (i,j) and Ψ (i,j), respectively;
-
4.
Set i = L;
For j = 1,..., 2ido
Combining equations (26), (27), and (30), solve S (i+1,2j) Δ x (i+1,2j) = b (i+1,2j) and S (i+1,2j-1) Δ x (i+1,2j-1) = b (i+1,2j-1) with Algorithm 1, where Δ x (i+1,2j-1), S (i+1,2j-1), and b (i+1,2j-1) are used instead of Δ x (i+1,2j), S (i+1,2j), and b (i+1,2j) when Algorithm 1 is employed for the latter case;
End for
-
5.
While i ≥ 0
{
For j = 1,..., 2ido
Substitute the solutions Δ x (i+1,2j) and Δ x (i+1,2j-1) into equation (23) to obtain the solution Δ x (i,j) at the i th level;
End for
i = i - 1;
}
-
6.
x 0 ← x 0 + Δ x (0,1);
-
7.
If ||Δ x (0,1)|| > ε
go to 2;
Else
x ← x 0, output x.
As mentioned before, the Schur complement system has a smaller condition number than that of the system from which it is constructed [7]. As a result, iterative methods based on the Schur complement systems can be more efficient than the methods based on the global matrix as in equation (20) due to its reduced scale and the smaller condition number. Therefore, the proposed algorithm can be expected to be more efficient than the conventional ones, as the results demonstrated in the next section.
Results and Discussion
In this work, assuming that the scattering coefficients are known, we focus on the reconstruction of the absorption coefficient μ axf . Two phantoms as illustrated in Figure 2 are used to evaluate the proposed algorithm. Figure 2(a) contains one object, and Figure 2(b) contains two objects of different shapes. Table 1 and Table 2 outline the optical and fluorescent parameters in different regions of the simulated phantoms corresponding to Figures 2(a) and 2(b), respectively. Four sources and thirty detectors are equally distributed around the circumference of the simulated phantom. The simulated forward data are obtained from equations (1) and (2), in which Gaussian noise with a signal-to-noise ratio of 10dB is added to evaluate the noise robustness of the algorithms. The parameters c 1 and c 2 in equation (19) are, respectively, set to 0.2 and 2. The initial guesses for solutions Δ x (i+1,2j) and Δ x (i+1,2j-1) of equations (29) and (31) are set to 0. The initial value of x 0 is set to 5 mm-1. The subspace created from the right singular vectors of the singular value decomposition (SVD) is optimal. Since SVD is computationally expensive, it is expected that a subspace close to SVD subspace will do almost as good. Thus, the choice of an oscillatory basis can be a basis created by sine or cosine functions with increasing frequency [26]. Here discrete cosine basis is employed in the simulations. To reliably evaluate the performance of different methods for the inverse problem, the best way is to use an independent forward model, which is different from the one employed in the inverse problem, to generate the synthetic data [27]. Therefore, in our case, a finer mesh as shown in Figure 3 with 169 nodes and 294 triangular elements is used to generate the forward simulated data.

Simulated phantoms for FMT. (a) One object with absorption coefficient μ axf of 0.2 mm-1 on the background medium with μ axf of 0.06 mm-1, and (b) two objects of different shapes, one of which with high absorption coefficient of 0.2 mm-1 and the other with low absorption coefficient of 0.15 mm-1, and the background medium with absorption coefficient of 0.06 mm-1.

Mesh used for forward solver of FMT. The mesh contains 169 nodes and 294 triangular elements.
It is well known that the most significant superiority of the anatomical imaging modality lies in the high spatial resolution. Hence, it will be helpful to improve the image quality and accelerate the reconstruction process if we use the anatomical image as prior information for mesh generation. The reconstructed domain is firstly uniformly discretized according to the Delaunay triangulation scheme, after which the uniform mesh is refined only for the areas with large variations of the pixel values. To simulate this idea, we employ the images shown in Figures 4(a) and 4(b) with a resolution of 100 × 100 pixels as the prior images corresponding to Figures 2(a) and 2(b), respectively. The meshes are generated as shown in Figure 5 for the inverse problem of FMT. The mesh with 122 nodes and 212 triangular elements (Figure 5(a)), and the mesh with 148 nodes and 264 triangular elements (Figure 5(b)) are generated incorporating the prior information as shown in Figures 4(a) and 4(b), respectively.

Model of prior image. (a) The prior image corresponds to Figure 2(a), and (b) the prior image corresponds to Figure 2(b).

Meshes used for inverse problem of FMT. (a) Mesh with 122 nodes and 212 triangular elements, and (b) mesh with 148 nodes and 264 triangular elements..
Figures 6(a) and 6(b) show, respectively, the reconstructed images of μ axf for one object phantom using the adaptive regularization scheme and Tikhonov regularization method. Figures 7(a) and 7(b) depict the results for two objects phantom from the above two different algorithms. Here, both of the results from Figures 6 and 7 are based on the CG method. As seen from Figures 6 and 7, better reconstructed results can be achieved from the adaptive regularization scheme. To quantitatively assess the accuracy of the different algorithms, the mean square error (MSE) is introduced

Reconstructed images of absorption coefficient due to exogenous fluorophores μ axf for one object. (a) Reconstructed result with the adaptive regularization scheme, and (b) reconstructed result with the Tikhonov regularization method.

Reconstructed images of absorption coefficient due to exogenous fluorophores μ axf for two objects. (a) Reconstructed result with the adaptive regularization scheme, and (b) reconstructed result with the Tikhonov regularization method.

where N is the total number of nodes in the domain. The superscript calc denotes the values obtained using reconstruction algorithms; and actual denotes the actual distribution of μ axf which is used to generate the synthetic image data set. Table 3 lists the performance of the reconstruction algorithms in terms of MSE. It can be seen that the adaptive regularization scheme can significantly improve the quality of the reconstructed images and achieve a smaller MSE in either case.
Figure 8 shows the reconstructed images of μ axf for one object phantom using the different algorithms after 1, 15, and 30 iterations, respectively. After 30 iterations, the reconstructed image from the proposed algorithm has a relatively higher contrast than those obtained from the other two algorithms. Figure 9 depicts the reconstructed images of μ axf for two objects phantom using the different algorithms, from which it can be seen that the proposed method can reconstruct the images more accurately than the other two methods even after the first iteration. According to the third column of Figure 9, the reconstructed image quality based on our algorithm is significantly improved as compared with that based on the other two methods.

Reconstructed images of absorption coefficient due to exogenous fluorophores μ axf for one object. (a)-(c) with the CG method, (d)-(f) with the Schur CG method, and (g)-(i) with our method. The reconstruction results after one iteration are shown in the first column, 15 iterations in the second column, and 30 iterations in the third column.

Reconstructed images of absorption coefficient due to exogenous fluorophores μ axf for two objects.(a)-(c) with the CG method, (d)-(f) with the Schur CG method, and (g)-(i) with our method. The reconstruction results after one iteration are shown in the first column, 15 iterations in the second column, and 30 iterations in the third column.
We investigated how the MSE changed against the number of iterations for different algorithms. Figure 10 shows a fast convergence of our algorithm with a less MSE than the other two algorithms. In addition, the CG method converges slower than the Schur CG method and our method, which means that solving the inverse problem based on the Schur complement system is superior to that based on the global system. The computation time of different algorithms is further investigated in our work to evaluate the convergence rate. Table 4 lists the computation time after 30 iterations for different algorithms. From this table, it can be seen that the time needed for our algorithm after 30 iterations is less than that of the Schur CG method. Although the former is a little bit longer than the time needed for the CG method, our algorithm needs only less than 5 iterations to achieve the precision of the CG method after 30 iterations. As a result, the CG method needs much more iterations to achieve a given precision of reconstruction than our method. Therefore, compared with the other two methods, the proposed algorithm is more efficient and stable.

Number of iterations versus MSE between the original and the reconstructed images. (a) Reconstruction of one object, and (b) reconstruction of two objects.
To further validate the proposed algorithm for 3D reconstruction, a phantom as illustrated in Figure 11 is used for simulations. Within this phantom, a small cylindrical object is suspended. In Figure 11, the dashed curves represent the planes of measurements. Four sources and sixteen measurements are used for each plane in the simulations. The mesh for reconstructing the 3D image is shown in Figure 12, which contains 858 nodes and 3208 tetrahedral elements. Figures 13 and 14 depict the reconstructed 2D cross sections of the 3D phantom shown in Figure 11 using the Schur CG method and the proposed algorithm, respectively. Table 5 lists the performance of the above two methods for a quantitative comparison. From this table, we can conclude that our proposed algorithm can also speed up the reconstruction process and achieve high accuracy for the 3D case.

Simulated phantom for 3D reconstruction. The phantom of radius 10 mm and height 40 mm with a uniform background of μ axf = 0.005mm-1 , which is positioned at x = 10mm, y = 0mm and z = 20mm. The small cylindrical anomaly has a radius of 2 mm and height 6 mm with μ axf = 0.01mm-1. The anomaly is positioned at x = 15mm, y = 0mm and z = 20mm. The dashed curves represent the measurement planes, at z = 15mm, z = 20mm, z = 25mm.

3D mesh for image reconstruction. 3D mesh for image reconstruction with 858 nodes and 3208 tetrahedral elements.

Reconstructed images using the Schur CG method. Reconstructed images using the Schur CG method, which are 2D cross sections through the reconstructed 3D volume. The right-hand side corresponds to the top of the cylinder (z = 40 mm), and the left corresponds to the bottom of the cylinder (z = 0 mm), with each slice representing a 10 mm increment.

Reconstructed images using the proposed algorithm. Reconstructed images using the proposed algorithm, which are 2D cross sections through the reconstructed 3D volume. The right-hand side corresponds to the top of the cylinder (z = 40 mm), and the left corresponds to the bottom of the cylinder (z = 0 mm), with each slice representing a 10 mm increment.
Conclusion
In this paper, we developed a novel image reconstruction method of FMT, based on the tree structured Schur complement decomposition in combination with the adaptive regularization scheme. The proposed approach decomposes the global inverse problem level by level with the Schur complement decomposition, and the resultant subsystems are solved with the biconjugate gradient method. The spatially variant regularization parameter is determined adaptively according to the objective function. Simulation results demonstrate that the proposed method outperforms the previous methods, such as the CG and the Schur CG methods, in both reconstruction accuracy and speed.
References
Boas DA, Brooks DH, Miller EL, DiMarzio CA, Kilmer M, Gaudette RJ, Zhang Q: Imaging the body with diffuse optical tomography. IEEE Signal Processing Mag 2001, 18: 57–75. 10.1109/79.962278
Ntziachristos V: Fluorescence Molecular Imaging. Annual Review of Biomedical Engineering 2006, 8: 1–33. 10.1146/annurev.bioeng.8.061505.095831
Ntziachristos V, Ripoll J, Wang LHV, Weissleder R: Looking and listening to light: the evolution of whole-body photonic imaging. Nat Biotechnol 2005, 23: 313–320. 10.1038/nbt1074
Milstein AB, Oh S, Webb KJ, Bouman CA: Direct reconstruction of kinetic parameter images in fluorescence optical diffusion tomography. IEEE International Symposium on Biomedical Imaging 2004, 1107–1110.
Reynolds JS, Troy TL, Mayer RH, Thompson AB, Waters DJ, Cornell KK, Snyder PW, Sevick-Muraca EM: Imaging of spontaneous canine mammary tumors using fluorescent contrast agents. Photochem Photobiol 1999, 70: 87–94. 10.1111/j.1751-1097.1999.tb01953.x
Fedele F, Eppstein MJ, Laible JP, Godavarty A, Sevick-Muraca EM: Fluorescence photon migration by the boundary element method. J Comput Phys 2005, 210: 109–132. 10.1016/j.jcp.2005.04.003
Axelsson O: Iterative Solution Methods. Cambridge University Press; 1994.
Tarvainen T, Vauhkonen M, Arridge SR: Gauss Newton reconstruction method for optical tomography using the finite element solution of the radiative transfer equation. J Quant Spectrosc Radiat Transfer 2008, 109: 2767–2778. 10.1016/j.jqsrt.2008.08.006
Haynsworth E: On the Schur complement. Basel Math Notes 1968., 20:
Zhao B, Wang H, Chen X, Shi X, Yang W: Linearized solution to electrical impedance tomography based on the Schur conjugate gradient method. Meas Sci Technol 2007, 18: 3373–3383. 10.1088/0957-0233/18/11/017
Silva AD, Dinten JM, Peltié P, Coll JL, Rizo P: In vivo fluorescence molecular optical imaging: from small animal towards clinical applications. 16th Mediterranean Conference on Control and Automation, Congress Centre, Ajaccio, France 2008, 1335–1340. full_text
Gibson AP, Hebden JC, Arridge SR: Recent advances in diffuse optical imaging. Phys Med Biol 2005, 50: R1-R43. 10.1088/0031-9155/50/4/R01
Lin Q: Basic text book of numerical solution method for differential equation. Volume 2003. 2nd edition. Science Press;
Paithankar DY, Chen AU, Pogue BW, Patterson MS, Sevick-Muraca EM: Imaging of fluorescent yield and lifetime from multiply scattered light reemitted from random media. Appl Opt 1997, 36: 2260–2272. 10.1364/AO.36.002260
Arridge SR, Schweiger M: A general framework for iterative reconstruction algorithms in optical tomography using a finite element method. In Computational Radiology and Imaging: Therapy and Diagnosis. Volume 110. Edited by: Borgers C, Natterer F. IMA Volumes in Mathematics and Its Applications, Springer-Verlag; 1998:45–70.
Magnus JR, Neudecker H: Matrix Differential Calculus with Applications in Statistics and Econometrics. In Wiley Series in Probability and Statistics. New York: Wiley; 1988.
Kaipio J, Somersalo E: Statistical and Computational Inverse Problems. Springer; 2005.
Roy R, Godavarty A, Sevick-Muraca EM: Fluorescence-Enhanced Optical Tomography Using Referenced Measurements of Heterogeneous Media. IEEE Trans Med Imaging 2003, 22: 824–836. 10.1109/TMI.2003.815072
Tikhonov AN, Arsenin VY: Solution of Ill-Posed Problems. Washington, DC: Winston; 1977.
Pogue BW, Patterson MS, Farrell TJ: Forward and inverse calculations for 3-D frequency-domain diffuse optical tomography. In In Optical Tomography, Photon Migration, and Spectroscopy of Tissue and Model Media: Theory, Human Studies, and Instrumentation. Proc SPIE 2389 Edited by: Chance B, Alfano RR. 1995, 328–339.
Pogue BW, McBride TO, Prewitt J, Osterberg UL, Paulsen KD: Spatially variant regularization improves diffuse optical tomography. Appl Opt 1999, 38: 2950–2961. 10.1364/AO.38.002950
Jennings A: Matrix Computation. Wiley; 1992.
Sarkar TK: On the Application of the Generalized BiConjugate Gradient Method. J Electromagnetic Waves and Applications 1987, 1: 223–242. 10.1163/156939387X00036
Liu SW, Sung JC, Lin MS: Scattering of antiplane impact waves by cracks in a layered elastic solid. Computer Methods in Applied Mechanics and Engineering 1998, 156: 335–349. 10.1016/S0045-7825(97)00217-X
Langtangen HP, Tveito A: A numerical comparison of conjugate gradient-like methods. Comm Appl Numer Methods 1988, 4: 793–798. 10.1002/cnm.1630040613
Jacobsen M: Two-grid iterative methods for ill-posed problems. In Master Thesis. Technical University of Denmark, Denmark; 2000.
Colton D, Kress R: Inverse Acoustic and Electromagnetic Scattering Theory. Springer; 1998.
Acknowledgements
This research is supported by the National Natural Science Foundation of China, No.60871086, the Natural Science Foundation of Jiangsu Province China No.BK2008159, the CSC Scholarship, PolyU, and ARC grants.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors' contributions
WZ conceived the study, implemented the algorithm, and drafted the initial manuscript. JJW participated in the design of the study, analyzed the simulation results, and helped to draft the manuscript. DDF critically reviewed the manuscript, helped to analyze the results, revised the manuscript, and provided the valuable advice.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Rights and permissions
Open Access This article is published under license to BioMed Central Ltd. This is an Open Access article is distributed under the terms of the Creative Commons Attribution License ( https://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Zou, W., Wang, J. & Feng, D.D. Image reconstruction of fluorescent molecular tomography based on the tree structured Schur complement decomposition. BioMed Eng OnLine 9, 20 (2010). https://doi.org/10.1186/1475-925X-9-20
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1475-925X-9-20