- Research
- Open access
- Published:
Sparse CT reconstruction based on multi-direction anisotropic total variation (MDATV)
BioMedical Engineering OnLine volume 13, Article number: 92 (2014)
Abstract
Background
The sparse CT (Computed Tomography), inspired by compressed sensing, means to introduce a prior information of image sparsity into CT reconstruction to reduce the input projections so as to reduce the potential threat of incremental X-ray dose to patients’ health. Recently, many remarkable works were concentrated on the sparse CT reconstruction from sparse (limited-angle or few-view style) projections. In this paper we would like to incorporate more prior information into the sparse CT reconstruction for improvement of performance. It is known decades ago that the given projection directions can provide information about the directions of edges in the restored CT image. ATV (Anisotropic Total Variation), a TV (Total Variation) norm based regularization, could use the prior information of image sparsity and edge direction simultaneously. But ATV can only represent the edge information in few directions and lose much prior information of image edges in other directions.
Methods
To sufficiently use the prior information of edge directions, a novel MDATV (Multi-Direction Anisotropic Total Variation) is proposed. In this paper we introduce the 2D-IGS (Two Dimensional Image Gradient Space), and combined the coordinate rotation transform with 2D-IGS to represent edge information in multiple directions. Then by incorporating this multi-direction representation into ATV norm we get the MDATV regularization. To solve the optimization problem based on the MDATV regularization, a novel ART (algebraic reconstruction technique) + MDATV scheme is outlined. And NESTA (NESTerov’s Algorithm) is proposed to replace GD (Gradient Descent) for minimizing the TV-based regularization.
Results
The numerical and real data experiments demonstrate that MDATV based iterative reconstruction improved the quality of restored image. NESTA is more suitable than GD for minimization of TV-based regularization.
Conclusions
MDATV regularization can sufficiently use the prior information of image sparsity and edge information simultaneously. By incorporating more prior information, MDATV based approach could reconstruct the image more exactly.
Background
CT (Computed Tomography) is one of the most important medical image technologies. Due to the potential cancer risk associated with the radiation dose in CT, recent technical development focuses on reducing radiation dose in CT. Several CT machine manufacturers have developed CT machines with iterative reconstruction algorithms to reduce radiation dose, such as the IRIS (Iterative Reconstruction in Image Space) of Siemens, ASiR (Adaptive Statistical Iterative Reconstruction) of GE (General Electric Co.), iDose (a trademark) of Philips and AIDR (Adaptive Iterative Dose Reduction) 3-D of Toshiba, which are reported to reduce the radiation dose by 30-50% while maintaining the reconstructed image quality comparable to the conventional FBP (Filtered Back Projection) method [1–5].
On the other hand, biomedical engineering researchers are trying to improve the performance of the iterative reconstruction algorithms by introducing more prior information of the reconstructed images to reduce the projection input and the radiation dose even more. One important prior information is image sparsity, whose usefulness has been testified by the recent popular compressed sensing technique in signal processing [6–8]. Before the compressed sensing, the sparsity of medical images has been used for limited-angle tomography [9] and few-view CT blood-vessel reconstruction [10]. Then following the compressed sensing theory, two kinds of sparse models were proposed for the sparse CT reconstruction. By ‘sparse CT’ we mean two aspects. First, a single CT image is approximately sparse like other natural images, and the information changes between successive CT images in dynamic CT are also approximately sparse. Second, the projection data is sparsely collected, such as limited-angle tomography [9] and few-view CT [10], rather than the full view dense collection in conventional CT scan. The first model uses the sparsity coming from the gradient transformation of the image which is assumed to be approximately piecewise-constant, such as ART-TV-MIN (Algebraic Reconstruction Technique Total Variation MINimization) [11] and ASD-POCS (Adaptive Steepest Descent Projection Onto Convex Sets) [12]. The second model uses the sparsity coming from the subtraction of the reconstructed image from its prior image, such as PICCS (Prior Image Constrained Compressed Sensing) [13], PIRPLE (Prior Image Registered Penalized Likelihood Estimation) [14, 15] and FCCS (Feature Constrained Compressed Sensing) [16].
In this paper we consider the methods based on the first model for the sparse CT reconstruction problems. In this model, the reconstruction problem can be written as a constrained optimization
The equality constraint is a guarantee of the data fidelity, where ℳ is the projection matrix modeling the forward projection, is the image vector to be restored, and is the projection vector. The objective function is a norm function of , which is a regularization for introducing some prior information like image sparsity. By using norm function of , we want to obtain a sparse solution of this constrained optimization. Therefore, sparser is, smaller should be. A commonly used norm function is TV (Total Variation) norm [11]. The optimization problem can also be written as an unconstrained form
where is a regularization parameter adjusting the relative penalties on the sparseness and the data fidelity.
To promote the performance of sparse CT reconstruction, two kinds of improvements are often considered. The first kind of improvement focuses on the sparsity regularization. Sidky [17] proposed the sparser TpV (Total p-Variation) norm to replace the TV norm. Yu [18] used the Haar wavelet transformation to make use of sparsity. Jia [19] replaced the TV norm with tight frame and used GPU (Graphics Processing Unit) to accelerate the reconstruction speed. Apart from replacement of TV norm, Tian [20], Liu [21], and Chang [22] developed some adaptive adjustment factors embedded in the TV norm to enhance the edge characteristic. Recently, Liu [23] introduced the TV-Stokes regularizer into sparse CT, which can smooth the isophote in the target image so as to preserve the detail and smoothness of the reconstructed image. The second kind of improvement focuses on the algorithms for resolving (2), which include CG (Conjugate Gradient) [24], forward backward splitting plus GPU [25], split-bregman [26], GPBB (Gradient Projection Barzilai Borwein) plus GPU [27], Chambolee-Pock algorithm [28], and ADMM (Alternating Direction Method of Multipliers) [29]. Besides, Niu and Zhu [30] proposed to use the log-barrier term to approximate the data fidelity term, which removes the forward and backward projection in the traditional iterative algorithms like ART (Algebraic Reconstruction Technique).
In this paper, we consider the first kind of improvement. The MDATV (Multi-Direction Anisotropic Total Variation) is proposed to replace TV norm. The aim of MDATV is to introduce into sparse CT reconstruction more prior information of edges, as the ATV (Anisotropic Total Variation) does [31, 32]. But ATV can only represent the edge information in few directions, which loses much prior information of edge directions. This paper combines the coordinate rotation transform with 2D-IGS (Two Dimensional Image Gradient Space), and represents the edge information in multiple directions easily. Based on this multi-direction representation, MDATV can incorporate more edge information into the sparse CT reconstruction, so as to improve the performance.
The rest of the paper is organized as follows. In section Methods, firstly, the background of ART and ATV is reviewed. Then the MDATV norm and its corresponding minimization methods are described. Finally, the ART + MDATV scheme is outlined. Section Simulations and experiments uses the proposed MDATV based approach to solve sparse CT reconstruction problems in numerical simulations and with experimental data, so as to demonstrate its remarkable efficiency. Finally, we conclude with section Discussions and conclusions, discussing the pros and cons of MDATV.
Methods
Review of ART + ATV
ART
The ART + ATV is proposed based on ART + TV method [11, 12]. ART updates the estimated image iteratively. Firstly, the estimated image is forward projected into the sinogram space, then the difference between the estimated sinogram and the given projections is back projected into the image space to update the estimated image. These steps are operated iteratively until some termination criteria are met. This method is also known as POCS (Projection Onto Convex Sets) in linear algebra. The ART update formula is as following
where g m is the m th element of the projection . is the m th row vector of the projection matrix ℳ. is the estimated image after fusing the m th element of the projection data during the n th iteration. The superscript T represents transpose.
TV and ATV
The TV norm in the ART + TV method is used to introduce and strengthen the prior information of image sparsity. This prior information significantly improves the quality of reconstructed image with low computation load. The TV norm is defined as
where f i,j is the pixel on the i th row and the j th column in the target image. D i f i,j =f i,j -f i–1,j , and D j f i,j =f i,j -f i,j–1 are the vertical and the horizontal gradients respectively, D i and D j are the corresponding finite differential operators. Because the image edges are orthogonal to their corresponding gradients, D i f i,j and D j f i,j can also represent edges in the horizontal and the vertical directions respectively. The TV norm is isotropic, since it assigns the same energy to both the vertical and the horizontal gradients. Different from TV norm, ATV norm is anisotropic and defined as
where A and B are weights controlling the energy ratios of the vertical and the horizontal gradients, respectively. When A = B, it is isotropic, else it is anisotropic. (4) can also be written as
where η=A/B is the weight factor. Therefore, we only need one parameter to control the energy ratios of the vertical and the horizontal gradients without affecting the results of optimization. In this paper we set η=1000. Based on experiments, this value of η can make the edges in the enhanced direction strong enough, while the potential artifacts in the suppressed direction weak enough. When η is smaller, the suppression to the potential artifacts may be not sufficient. A bigger η is also valid, but the reconstructions hardly change any more.
Motivation of ATV
The motivation of ATV is to introduce into sparse CT reconstruction a prior information of edge directions. This prior information was discovered by Quinto [33] decades ago. In sparse CT reconstruction, the edge information tangent to the projection rays would be measured and restored easily, while those not tangent to the projection rays should be harder to ‘see’. This phenomenon can be theoretically explained by the central slice theory [34].
Without loss of generality, we take the parallel projection for example. This example is shown in Figure 1. Suppose the projection rays in direction a produce a row of projections. Each point of the projection row corresponds to one projection ray, and each point’s value is the linear integration of the attenuation coefficients passed through by the corresponding projection ray. According to the central slice theory, the 1-D Fourier transformation of this projection row is the central slice perpendicular to a in the Fourier frequency space. In the 2D Fourier space, the central slice is a line passing through the origin. Thereby the projection data collected by projection rays in direction a corresponds to a central slice perpendicular to a in the 2D Fourier space.

Central slice theory.
According to the Fourier optics [35], if a family of edges in a 2D image are in the direction a, then the Fourier transformation of these edges is a line passing through the origin and perpendicular to a in the 2D Fourier frequency space, as shown in Figure 2. This means that the line passing through the origin and perpendicular to a in the 2D Fourier space corresponds to the edge information in direction a of the 2D image.

Edges’ direction in 2D image (left column) is perpendicular to their corresponding Fourier transformation’s direction (right column).
Compare Figures 1 and 2, we find that the projection rays in direction a record the edge information in the same direction. Therefore, the edge information tangent to the projection rays would be restored easily, since these edge information is well recorded by the projection rays. While the edge information perpendicular to the projection rays is not recorded, thereby these edges are hard to ‘see’.
The discussion above indicates that the geometrical information of projection may affect the sparse CT reconstruction. For example in the limited-angle projection, if most projections are tangent or approximately tangent to the horizontal direction, then the isotropic TV regularization may result in some artifacts in the vertical direction, which will blur the clear edges in the horizontal direction. Since the projections did not record any edge information in the vertical direction, the energy vacancy in the vertical direction would be filled by artifacts. However, ATV could handle this problem by assigning more energy in the horizontal direction and less energy in the vertical direction, thus to enhance the edge information in the horizontal direction and suppress the artifacts in the vertical direction.
MDATV
However, ATV can only represent edges in few directions. This may lose much prior information of edges in many other directions. To remedy this defect, MDATV is proposed to use the entire prior information of edges.
2D-IGS
Before description of MDATV, we firstly introduce the 2D-IGS. In a 2D discrete image, f i,j is defined as the pixel on the i th row and the j th column. The 2D-IGS contains two parts. One is the vertical edges denoted by the 2D matrix E v , and the other is the horizontal edges denoted by the 2D matrix E h . They are defined as
where D v and D h are the same as D i and D j in (3) representing the vertical and the horizontal finite differential operators respectively. The E h and E v of Shepp-Logan phantom are shown in Figure 3(b) and (e). The original image is generated by the function ‘phantom(128)’ in MATLAB®, as shown in Figure 3(a).

The Shepp-Logan phantom and edges. (a) The original Shepp-Logan phantom with display gray scale window of [0,1], (b) its horizontal edges E h , (c) rotated horizontal edges E hr , (d) gradient image with display gray scale window of [0,0.01], and (e) vertical edges E v , (f) rotated vertical edges E vr . The edges are rotated counterclockwise by 45°.
Edges in multiple directions
E h and E v represent the horizontal and the vertical edges of the 2D image, which are used in the TV and ATV norm. To represent edges in many more other directions, the coordinate rotation transform is introduced to be applied to the 2D-IGS.
First, we recall the elementary coordinate rotation transform in 2D space. Figure 4 shows the transform process. The coordinate system xOy rotates counterclockwise by θ degrees to the coordinate system x′Oy′, where 0° ≤ θ ≤ 180°. The target point T in xOy is denoted by (x 0, y 0). Its corresponding rotated target point T′ is denoted by in x′Oy′. Obviously, we have and . When we need to process the rotated target point T′ in xOy, we can project the coordinates of T′ in x′Oy′ onto the coordinate system xOy. Let (p, q) denote the projected coordinates of T′ in xOy. According to the elementary geometry, the transform formula is

Coordinates system xOy rotates counterclockwise by θ degrees to coordinate system x′Oy′.
where p is the linear combination of the projections of and onto the x axis. q is the linear combination of the projections of and onto the y axis.
When the coordinate rotation transform is applied to the 2D-IGS , the horizontal edges E h corresponds to the horizontal line segment x 0 in (6), and the vertical edges E v corresponds to the vertical line segment y 0 in (6). After counterclockwise rotation by degrees, we get the rotated 2D-IGS Ψ′, which contains the rotated horizontal and vertical edges and . But we need to process the rotated horizontal and vertical edges in the 2D-IGS . Therefore, we need to project and onto the 2D-IGS . Let E hr and E vr denote the projected and . Then E hr and E vr correspond to p and q in (6). Thus we have
By adjusting the angle , the edges in any direction could be denoted by (7). The rotated edges E hr and E vr of Shepp-Logan phantom are shown in Figure 3(c) and (f) with the rotation angle of –45°. Based on (5), (7) could be rewritten by the finite differential operators
where D vr and D hr are the rotated vertical and horizontal finite differential operators.
MDATV
Based on the multi-direction representation, the MDATV is defined as
where E h and E v are defined in (5), is the weights adjusting the the energy ratios of the rotated horizontal and vertical edges. Substitute (7) into (8), we get the simplified form of (8)
In this paper we set = 1000 with the same reason in ATV. Therefore, the rotated horizontal edges E hr are representing the edges parallel to the projection rays. If < 1, then the rotated vertical edges E vr would represent the edges parallel to the projection rays.
In optimization problem (1), the objective function is some kind of norm function, such as TV, ATV or MDATV. Whatever the objective function is, the optimization requires to minimize this function. One common method for minimization is gradient descent (GD). Thus we need to compute the gradient of MDATV. Substitute (5) into (8) and the MDATV’s gradient is
where
and ϵ is a small positive constant to avoid the singularity. In this paper we set ϵ = 1.0 × 10- 8.
Minimization approaches
GD (Gradient Descent)
The workflow of GD for minimizing regularization in optimization (1) is as following:
-
a)
Compute the balancing parameter between ART (data fidelity) and GD (regularization)
-
b)
for k = 1,2,… K
end for
Where and are the estimated image before and after the J th iteration of ART respectively, and is the step size. Although the variable d is kind of useful for adaptively adjusting the step size of GD, is determinant in practice.
Note that the norm of is smaller than the norm of . In GD there usually is a fixed best step size * such that the convergence rate is fastest. This * may be found by the traversal method, which tries many step sizes for the problem and finds the best one within a given accuracy. Obviously, smaller the gradient vector is, bigger the best step size * is. The bigger step size is more resistant to the perturbation. For example, the perturbation of 0.1 is negligible for the step size of 50, but this perturbation would have a significant impact for the step size of 0.01. Therefore, we use instead of as the gradient vector in this paper.
However, in optimization (1), GD is not a stable method for minimizing TV, ATV or MDATV regularizations. Since the best step size of GD changes greatly with the projection parameters and the target images. And the imperfect step size may greatly slow down the convergence rate and degenerate the quality of the estimated image. To overcome this defect of GD, the NESTA (NESTerov’s algorithm) [36] method is proposed to minimize the regularizations in (1).
NESTA
Because the MDATV could be expressed as
where . The form of MDATV norm in (10) is the same as the TV norm in (3), which is almost the similar for ATV and TV. Thus we can first study the NESTA method for TV minimization and then apply the conclusions to ATV and MDATV minimization.
NESTA, based on the Nesterove’s smoothing technique [37], is a fast first-order method for sparse recovery. First, the nonsmooth TV norm can be rewritten as
where , the convex set is referred to as the primal feasible set. u = [u 1, u 2]T is in the dual feasible set if and only if , and Df i,j = [D h f i,j ,D v f i,j ]T is the finite difference of the 2D image f i,j . The superscript T denotes transpose. If u is regarded as a 2D vector, then is a ℓ 2 norm unit ball.
According to Nesterov’s work, the smoothed TV regularization function is  (12)
(12)
where should be set sufficiently small such that  . Here we set = 0.01. Then
. Here we set = 0.01. Then  is given by
is given by (13)
(13)
Where D = [D h ,D v ]T, is of the form [u 1 ,u 2 ]T and for each a ∈ {h, v},
The minimization of the smoothed TV norm by Nesterov’s algorithm is obtained by iteratively estimating three sequences , , and as follows:
Initialize . for k = 1,2,…,K,
-
a)
Compute
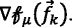
-
b)
Compute
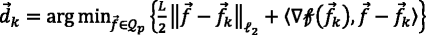 (14)
(14) -
c)
Compute
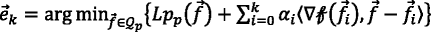 (15)
(15) -
d)
Update
(16)
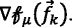
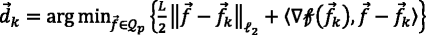
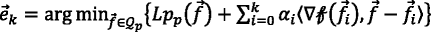
end for.
In the above algorithm, α i = (i + 1)/2, τ k = 2/(k + 3) is suggested for fast convergence. Since the goal is minimizing TV norm without other constraints, and can be computed by letting the gradients of the object functions be zero and then we get

In (15), a suitable smoothing prox-function is
Then we have

Some other preset parameters are
ART + MDATV scheme
In this paper, the data fidelity constraint is processed by ART iteration, and the MDATV regularization is minimized by NESTA. To use the prior information of the edges in multiple directions, the original ART + TV scheme [11] is not suitable for MDATV regularization. In the ART + TV scheme, firstly, the overall projection data are used to update the estimated image through ART. Then the estimated image is used as the input of the minimization method. The ART and the minimization is operated alternately. Each pair of successive ART and minimization constitutes an iteration of the ART + TV scheme. The workflow of the ART + TV scheme is shown below:

In the above scheme, the stopping criterion is the relative error between the estimated image and the true phantom image being less than 1.0 × 10–5. The relative error is computed as
where is the estimation of the restored image, is the original phantom image known as ground truth. || · || is the Frobenius norm.
However, the MDATV use the prior information of edges in multiple directions by adjusting the angle in (7). In the ART + TV scheme, there is no time to adjust . Therefore, the ART + MDATV scheme is proposed.
In the ART + MDATV scheme, projection data are divided into m groups based on the directions of the projection rays. In each group of projections, the projection rays are in the same direction for the parallel projection, and in the approximately same direction for the fan-beam projection. Thus each group of projections corresponds to an angle θ k (k = 1, 2, …, m), which specifies the location of the X-ray source. Then for the k th group of projections, the ART and the minimization of MDATV regularization of θ k are operated once successively. The estimated image of the k th group of projections is used as the initial estimate of the (k + 1)th group of projections. The process of the m groups of projections constitutes an iteration of the ART + MDATV scheme. The workflow of the ART + MDATV scheme is shown below:

The stopping criterion in the above scheme is the same as that in the ART + TV scheme. Based on the experiments, the iteration times of NESTA for MDATV is set as 10, and the iteration times of NESTA for TV and ATV are both set as 40.
Simulations and experiments
Numerical simulations and real data experiments are conducted to validate the performance of MDATV based approaches. The TV and ATV based approaches are used for comparison. To compare the stableness of GD and NESTA, for each method, they are respectively used for minimizing the regularizations. Therefore, the combination of ART with three different regularizations and two kinds of minimization methods leads to six approaches: ART-TV-GD, ART-TV-NESTA, ART-ATV-GD, ART-ATV-NESTA, ART-MDATV-GD, and ART-MDATV-NESTA. The simulations for noisy measurements are conducted for comparing the noise robustness of different regularizations. Finally, the real data experiment is used to testify the effectiveness of MDATV in practical applications. Besides, this paper uses the CT module in “Image reconstruction toolbox” [38] to construct the projection matrix and operate the forward and backward projections.
Numerical simulation
Simulation settings
To reduce the X-ray dose, reduction of projection rays is a natural option. There are two common styles for reducing the projection rays. They are limited-angle [9] and few-view [10] styles. The schematic diagrams of these two styles are shown in Figure 5. For the same number of projection views, the information of target image in the few-view style is much more than that in the limited-angle style. In this paper, we only describes the simulations of the few-view style.The phantom used in this paper is generated by the function ‘phantom(128)’ in MATLAB®, as shown in Figure 3(a). It has 128 × 128 pixels. The simulated X-ray detector has 240 bins for the fan-beam projection. And the size of the detector bin is 2 millimeters. In the fan-beam projection, the distance between the source and center of the detector is 960.45 millimeters, and the distance from the source to the origin is 628.88 millimeters.

Schematic diagram of ‘limited-angle’ and ‘few-view’ sparse projection styles.
According to the ERP (Exact Reconstruction Principle) [6], if the number of FT (Fourier Transform) samples is twice the number of non-zero pixels in the gradient image, then the optimization program (1) can yield a unique solution. The gradient image of Shepp-Logan phantom is shown in Figure 3(d), where the number of non-zero pixel is 1743. In the digital condition, according to the central slice theory [34], one projection data corresponds to one FT sample. Therefore, we need at least 1743 × 2 = 3486 projection data points. While the fan-beam detector has 240 bins, thus based on ERP we need 3486 ÷ 240 ≈ 15 views of projections. For comparison, we also take some less views of projections, such as 11 and 13 views, in the numerical simulations.
The best step sizes of GD are different when the projection style or the regularization changes. Table 1 lists the best step sizes of GD for the fan-beam projections with different regularizations and projection views. These best step sizes are obtained by the traversal method within the accuracy of 1. Since the perturbation within 1 rarely affects the convergence rate of GD.
To test the robustness of these methods to noise, the Poisson noise is introduced into the projections by the function ‘poisson’ in the “Image reconstruction toolbox” [38]. The incident photon number is set as 1.0 × 105. Table 2 lists the best step sizes of GD for the noisy reconstructions.
Visualization-based evaluation
The restored images from 11 views of noise-free and noisy projections are shown in Figure 6, and the restored images from 15 views of noise-free and noisy projections are shown in Figure 7. Both the observations of Figures 6 and 7 indicate that the TV and MDATV regularizations are obviously better than ATV regularization. There are some horizontal artifacts in the restored image of ATV methods, which is caused by the unbalanced regularization, while the projection data are uniformly distributed. It can also be observed that increased projection data prominently improved the image quality.

Restored images from 11 views of noise-free (top row) and noisy projections (bottom row) with methods of ART-TV-GD, ART-TV-NESTA, ART-ATV-GD, ART-ATV-NESTA, ART-MDATV-GD, and ART-MDATV-NESTA (from left to right) after 100 iterations. The display gray scale window is [0,1].

Restored images from 15 views of noise-free (top row) and noisy projections (bottom row) with methods of ART-TV-GD, ART-TV-NESTA, ART-ATV-GD, ART-ATV-NESTA, ART-MDATV-GD, and ART-MDATV-NESTA (from left to right) after 100 iterations. The display gray scale window is [0,1].
Profile-based evaluation
To further visualize the difference among various methods, vertical profiles of restored images were drawn across the 64th column, from the 1st row to the 128th row. Figures 8 and 9 shows the vertical profiles of the restored images in Figure 6 and the corresponding profile in the original Shepp-Logan phantom. And the vertical profiles of the restored images in Figure 7 and their corresponding profile in the original Shepp-Logan phantom are shown in Figures 10 and 11. The observations from all the profiles also indicate the same conclusion as the visualization-based evaluation.

Vertical profiles (64th column, 1st row to 128th row) of the images restored from 11 views of noise-free projections.

Vertical profiles (64th column, 1st row to 128th row) of the images restored from 11 views of noisy projections.

Vertical profiles (64th column, 1st row to 128th row) of the images restored from 15 views of noise-free projections.

Vertical profiles (64th column, 1st row to 128th row) of the images restored from 15 views of noisy projections.
Relative error study
The relative error is used in the simulation iterations as stopping criterion. Therefore, it can also be used to show the convergence condition of various methods. The curves of relative errors versus iteration times of reconstruction processes from 11 and 15 views of projections are shown in Figures 12 and 13. The observations indicate that after some iterations the reconstructions would converge to steady conditions. And the relative error after the final iteration can represent the reconstruction quality. For the 11 views condition, MDATV is better than TV, and TV is better than ATV. While for the 15 views condition, the three regularizations are hard to distinguish.

Relative error of reconstructions from 11 views of noise-free (top) and noisy (bottom) projections with six methods versus iterations.

Relative error of reconstructions from 15 views of noise-free (top) and noisy (bottom) projections with six methods versus iterations.
UQI (Universal Quality Index) study
To perform more quantitative analysis of these methods, the UQI [39] is introduced. UQI measures the similarity between the desired image and its ground truth image [23]. UQI value ranges between zero and one. A higher UQI value represents a higher similarity between the testing image and the ground truth image, and vice versa. The ROI (Region Of Interest) used for computing UQI is in the red rectangle as shown in Figure 3(a). The UQI values of restored images by various methods from different views of projections are plotted as several curves shown in Figure 14. The UQI values are in accord with the relative errors. The observations also indicate that the MDATV is better than TV, and TV is better than ATV. When the volume of projection data increase, the distinctions among these regularizations are decreasing.

UQI values of restored images by various methods from 11, 13 and 15 views of noise-free (top) and noisy (bottom) projections.
Real data experiment
To demonstrate the effectiveness of proposed method in real CT application, the real data experiment is conducted. The projection data is from a micro-CT machine in Tianjin Key Laboratory of Biomedical Detecting Techniques and Instruments. The scanning phantom is an organic glass column with three holes of different diameters, as shown in Figure 15. In this experiment, the left hole on top is empty (filled with air), the right hole on top is filled with corn flour, and the bottom hole is filled with a copper bar. The distance between the source and center of the detector is 960.45 millimeters, and the distance from the source to the origin is 628.88 millimeters.

Cross section of the organic glass column with three holes in real data experiment.
In the experiment, the detector has 1024 bins, and the physical size of each bin is 0.05 millimeters. Therefore, the raw sinogram of one view has 1024 pixels, and each pixel represents the physical length of 0.05 millimeters. However, the computation load of the iterative reconstruction is very heavy for the high resolution sinogram. Thus the high resolution sinogram is down sampled by the ratio of 4. And the low resolution sinogram of one view has 256 = 1024 ÷ 4 pixels. To maintain the physical length of the projection geometry, each pixel in the low resolution sinogram represents the physical length of 0.2 = 0.05 × 4 millimetres. Actually, in this down sampling, four neighboring pixels in the raw sinogram of one view is averaged as one pixel in the low resolution sinogram of one view.In this experiment, restrained by the micro-CT machine, the whole projection data contains 120 views of fan-beam projection uniformly distributed across 360°. Its FBP reconstruction is shown in Figure 16. Compare Figure 15 and 16, it is easy to distinguish the air and copper filled holes from the background organic glass, while the corn filled hole is hard to distinguish from the background organic glass. This is because that the attenuation coefficient of corn flour is very similar to that of the organic glass, while the attenuation coefficients of air and copper are very different from that of the organic glass.

Restored iamges from 120 views of fan-beam projections with FBP. The display gray scale window is [80,400].
For the sparse CT reconstruction experiment, 30 views of fan-beam projections are chose uniformly across the range of 360°. Due to the ATV’s poor performance for the sub-ERP projections (volume of projections is less than that required by ERP), we only compare TV and MDATV based methods. The reconstruction methods used in the experiments are ART-TV-GD, ART-MDATV-GD, and ART-MDATV-NESTA. The step sizes of GD used in the reconstructions are 92 for TV and 10 for MDATV, which are estimated from an approximate synthetic phantom. The iteration times of NESTA for MDATV is 40.In Figure 17, we show the reconstructions after 5 iterations (top row) and 100 iterations (bottom row) with three methods (from left to right): ART-TV-GD, ART-MDATV-GD, ART-MDATV-NESTA. In the restored images, the holes filled with air and copper are distinct, while the hole filled with corn is undistinguishable. To further visualize the difference among various methods, horizontal profiles of restored images were drawn across the 63rd row (for the air and corn filled holes) and 127th row (for the copper filled hole), from the 10th column to the 160th column. The profiles of restored images after 5 and 100 iteration are shown in Figure 18. Since the projection data is not sufficient, the FBP reconstructions abound with artifacts, but the FBP reconstructions clearly depict the boundaries of the air and copper filled holes. And the observations from Figure 18 indicate that MDATV-NESTA profiles matches the FBP profiles best.The regions of holes filled with air and copper (in the red rectangles in Figure 17) are zoomed in and shown in Figures 19 and 20 respectively. To increase the contrast of Figures 19 and 20, 5% of data is saturated at low and high intensities of the original image. Figures 19 and 20 indicate that ART-MDATV-GD method gave the best results. Since the restored circles by ART-MDATV-GD are the most round. The restored circles of ART-MDATV-NESTA are more round than that of ART-TV-GD. The radial artifacts in the restored images are metal artifacts, which can be removed by some off-the-shelf methods.

Restored images from 30 views of few-view style fan-beam projections after 5 iterations (top row) and 100 iterations (bottom row) with three methods (from left to right): ART-TV-GD, ART-MDATV-GD, ART-MDATV-NESTA. The display gray scale window is [80,400].

Horizontal profiles (63rd row (top) and 127th row (bottom), 1st column to 128th column) of the restored images after 5 (left) and 100 (right) iterations.

Restored circles representing the air filled hole in Figure 17 .

Restored circles representing the copper filled hole in Figure 17 .
Discussions and conclusions
The simulations and experiments both indicate that MDATV is a useful and robust regularization for the sparse CT reconstruction when the volume of the projection data is less than the volume required by the ERP. But actually, it is impossible to satisfy the ERP in practical applications. Because the practical target images are not piecewise-constant, which means the non-zero elements of the gradient image are infinite. Thus the volume of digital projections is always not enough. Therefore, using MDATV to incorporate more a prior information of the target images is valuable and gainful in practical applications, as shown in the real data experiment. And the indistinguishable results among the three regularizations with ERP projections in the simulations is because that the synthetic phantom is piecewise-constant, which means its ERP samples are limited. Obviously, when the projections’ volume satisfies the ERP, there is no need to incorporate any other prior information.
Since MDATV can represent edges in any direction, the MDATV based methods can use the prior information of edge directions more efficiently than TV or ATV based methods. Therefore, MDATV based methods could enhance the edges in the projection rays directions and suppress the potential artifacts in the no projection rays directions, which leads to the improvement of the reconstructions.
In this paper, NESTA is proposed to minimize the MDATV regularization instead of GD. This is because that NESTA gives almost the same results as GD does for minimization of the regularizations, but NESTA is more stable than GD. For example, Tables 1 and 2 list the best step sizes of GD used in the simulations. The best step size of GD changes much for different projections and noisy conditions. And there is no rule to obtain the best step size of GD in advance. Nevertheless, the few parameters in NESTA almost does not change in the simulations and experiments. Obviously, NESTA is a considerable choice for minimizing the regularizations in the sparse CT reconstruction.
The accumulated computation time of the simulations are listed in Table 3. It is observed that the computation load of NESTA is a little higher than that of GD, but NESTA is more stable than GD. If the comparison includes the time of finding the best step size of GD, then NESTA will be much faster than GD. Due to the special scheme of ART + MDATV, MDATV related methods need more computation time than TV or ATV related methods. This is because that MDATV related methods do the minimization after each group of ART iteration. If the projections are classified into m groups, then MDATV related methods have m - 1 times of minimization more than TV or ATV related methods. Furthermore, each minimization has several times of GD or NESTA iterations.
In addition, it is notable that the fan-beam geometry in the numerical simulations and real data experiment are the same, both from the geometry of the micro-CT machine. In this geometry, the view angle of the fan-beam projection is so small that the projection rays in the same projection view are approximately in the same direction. While in practical applications, the view angle of the fan-beam projection may be bigger so that the projection rays in the same projection view are not approximately in the same direction. In this condition, it needs to rearrange the projection data according to their corresponding projection directions, such that the projection rays having the approximately same direction can be classified into the same group. This will be one of our future research directions.
This paper proposed the MDATV regularization to sufficiently use a prior information of projection directions and image sparsity in the sparse CT reconstruction. Due to the effective use of prior information of projection directions, the restored edge information is greatly enhanced, and thus to improve the reconstructions. The numerical simulations and real data experiments demonstrate the advantage of MDATV over other regularizations. NESTA is proposed as an alternative to GD for minimizing the TV-based regularizations. Because NESTA is more stable and has the almost same performances as GD.
Otherwise, although the MDATV regularization method was only validated for fan-beam projections, it is simple to introduce this regularization approach to other tomography reconstructions. And using prior information of projection directions may further facilitate the development of tomography. Besides, we think the presentation of edges in multiple directions may have more applications in the fields of image enhancement and reconstruction.
Abbreviations
- MDATV:
-
Multi-direction anisotropic total variation
- CT:
-
Computed tomography
- ATV:
-
Anisotropic total variation
- TV:
-
Total variation
- 2D-IGS:
-
2-Dimensional image gradient space
- ART:
-
Algebraic reconstruction technique
- NESTA:
-
NESTerov’s algorithm
- GD:
-
Gradient descent
- IRIS:
-
Iterative reconstruction in image space
- ASiR:
-
Adaptive statistical iterative reconstruction
- GE:
-
General electric Co
- iDose:
-
trademark of Philips
- AIDR:
-
Adaptive iterative dose reduction
- FBP:
-
Filtered back projection
- ART-TV-MIN:
-
Algebraic reconstruction technique total variation MINimization
- ASD-POCS:
-
Adaptive steepest descent projection onto convex sets
- PICCS:
-
Prior image constrained compressed sensing
- PIRPLE:
-
Prior image registered penalized likelihood estimation
- FCCS:
-
Feature constrained compressed sensing
- TpV:
-
Total p-variation
- GPU:
-
Graphics processing unit
- CG:
-
Conjugate gradient
- GPBB:
-
Gradient projection Barzilai Borwein
- ADMM:
-
Alternating direction method of multipliers
- POCS:
-
Projection onto convex sets
- ERP:
-
Exact reconstruction principle
- FT:
-
Fourier transform
- UQI:
-
Universal quality index
- ROI:
-
Region of interest.
References
Schindera ST, Diedrichsen L, Muller HC, Rusch O, Marin D, Schmidt B, Raupach R, Vock P, Szucs-Farkas Z: Iterative reconstruction algorithm for abdominal multidetector CT at different tube voltages: assessment of diagnostic accuracy, image quality, and radiation dose in a phantom study. Radiology 2011,260(2):454–462.
Martinsen AC, Saether HK, Hol PK, Olsen DR, Skaane P: Iterative reconstruction reduces abdominal CT dose. Eur J Radiol 2012,81(7):1483–1487.
Deak Z, Grimm JM, Treitl M, Geyer LL, Linsenmaier U, Korner M, Reiser MF, Wirth S: Filtered back projection, adaptive statistical iterative reconstruction, and a model-based iterative reconstruction in abdominal CT: an experimental clinical study. Radiology 2013,266(1):197–206.
Wu TH, Hung SC, Sun JY, Lin CJ, Lin CH, Chiu CF, Liu MJ, Teng MM, Guo WY, Chang CY: How far can the radiation dose be lowered in head CT with iterative reconstruction? Analysis of imaging quality and diagnostic accuracy. Eur Radiol 2013,23(9):2612–2621.
Gervaise A, Osemont B, Lecocq S, Noel A, Micard E, Felblinger J, Blum A: CT image quality improvement using Adaptive Iterative Dose Reduction with wide-volume acquisition on 320-detector CT. Eur Radiol 2012,22(2):295–301.
Candès EJ, Romberg J, Tao T: Robust uncertainty principles: Exact signal reconstruction from highly incomplete frequency information. IEEE Trans Inf Theory 2006,52(2):489–509.
Candès EJ, Romberg JK, Tao T: Stable signal recovery from incomplete and inaccurate measurements. Comm Pure Appl Math 2006,59(8):1207–1223.
Candès EJ, Wakin MB: An introduction to compressive sampling. IEEE Signal Process Mag 2008,25(2):21–30.
Delaney AH, Bresler Y: Globally convergent edge-preserving regularized reconstruction: an application to limited-angle tomography. IEEE Trans Image Process 1998,7(2):204–221.
Li M, Yang H, Kudo H: An accurate iterative reconstruction algorithm for sparse objects: application to 3D blood vessel reconstruction from a limited number of projections. Phys Med Biol 2002,47(15):2599–2609.
Sidky EY, Kao C, Pan X: Accurate image reconstruction from few-views and limited-angle data in divergent-beam CT. J Xray Sci Technol 2006,14(2):119–139.
Sidky EY, Pan XC: Image reconstruction in circular cone-beam computed tomography by constrained, total-variation minimization. Phys Med Biol 2008,53(17):4777–4807.
Chen GH, Tang J, Leng S: Prior image constrained compressed sensing (PICCS): a method to accurately reconstruct dynamic CT images from highly undersampled projection data sets. Med Phys 2008,35(2):660–663.
Stayman JW, Otake Y, Prince JL, Khanna AJ, Siewerdsen JH: Model-based tomographic reconstruction of objects containing known components. IEEE Trans Med Imag 2012,31(10):1837–1848.
Stayman JW, Dang H, Ding Y, Siewerdsen JH: PIRPLE: a penalized-likelihood framework for incorporation of prior images in CT reconstruction. Phys Med Biol 2013,58(21):7563.
Wu D, Li L, Zhang L: Feature constrained compressed sensing CT image reconstruction from incomplete data via robust principal component analysis of the database. Phys Med Biol 2013,58(12):4047–4070.
Sidky EY, Pan X, Reiser IS, Nishikawa RM, Moore RH, Kopans DB: Enhanced imaging of microcalcifications in digital breast tomosynthesis through improved image-reconstruction algorithms. Med Phys 2009,36(11):4920–4932.
Yu H, Wang G: SART-type image reconstruction from a limited number of projections with the sparsity constraint. Int J Biomed Imaging 2010, 2010: 934847.
Jia X, Dong B, Lou Y, Jiang SB: GPU-based iterative cone-beam CT reconstruction using tight frame regularization. Phys Med Biol 2011,56(13):3787–3807.
Tian Z, Jia X, Yuan K, Pan T, Jiang SB: Low-dose CT reconstruction via edge-preserving total variation regularization. Phys Med Biol 2011,56(18):5949–5967.
Liu Y, Ma J, Fan Y, Liang Z: Adaptive-weighted total variation minimization for sparse data toward low-dose x-ray computed tomography image reconstruction. Phys Med Biol 2012,57(23):7923–7956.
Chang M, Li L, Chen Z, Xiao Y, Zhang L, Wang G: A few-view reweighted sparsity hunting (FRESH) method for CT image reconstruction. J Xray Sci Technol 2013,21(2):161–176.
Liu Y, Liang Z, Ma J, Lu H, Wang K, Zhang H, Moore W: Total variation-stokes strategy for sparse-view X-ray CT image reconstruction. IEEE T Med Imaging 2014,33(3):749–763.
Song J, Liu QH, Johnson GA, Badea CT: Sparseness prior based iterative image reconstruction for retrospectively gated cardiac micro-CT. Med Phys 2007,34(11):4476–4483.
Jia X, Lou Y, Li R, Song WY, Jiang SB: GPU-based fast cone beam CT reconstruction from undersampled and noisy projection data via total variation. Med Phys 2010,37(4):1757–1760.
Vandeghinste B, Goossens B, De Beenhouwer J, Pizurica A, Philips W, Vandenberghe S, Staelens S: Split-Bregman-based sparse-view CT reconstruction. 11th International meeting on Fully Three-Dimensional Image Reconstruction in Radiology and Nuclear Medicine (Fully 3D 11) 2011, 431–434.
Park JC, Song B, Kim JS, Park SH, Kim HK, Liu Z, Suh TS, Song WY: Fast compressed sensing-based CBCT reconstruction using Barzilai-Borwein formulation for application to on-line IGRT. Med Phys 2012,39(3):1207–1217.
Sidky EY, Jørgensen JH, Pan X: Convex optimization problem prototyping for image reconstruction in computed tomography with the Chambolle–Pock algorithm. Phys Med Biol 2012,57(10):3065.
Ramani S, Fessler JA: A splitting-based iterative algorithm for accelerated statistical X-ray CT reconstruction. IEEE Trans Med Imaging 2012,31(3):677–688.
Niu T, Zhu L: Accelerated barrier optimization compressed sensing (ABOCS) reconstruction for cone-beam CT: phantom studies. Med Phys 2012,39(7):4588–4598.
Jin X, Li L, Chen Z, Zhang L, Xing Y: Anisotropic total variation for limited-angle CT reconstruction. Nuclear Science Symposium Conference Record (NSS/MIC), IEEE 2010, 2232–2238.
Chen Z, Jin X, Li L, Wang G: A limited-angle CT reconstruction method based on anisotropic TV minimization. Phys Med Biol 2013,58(7):2119.
Quinto ET: Tomographic reconstructions from incomplete data-numerical inversion of the exterior Radon transform. Inverse Probl 1988,4(3):867.
Bracewell RN: Strip Integration in Radio Astronomy. Aust J Physics 1956,9(2):198–217.
Goodman JW: Introduction to Fourier optics, 2nd edn: McGraw-Hill Companies. 1996.
Becker S, Bobin J, Candès E: NESTA: a fast and accurate first-order method for sparse recovery. SIAM J Imaging Sci 2011,4(1):1–39.
Nesterov Y: Smooth minimization of non-smooth functions. Math Program 2005, 103: 127–152.
Fessler J: Image reconstruction toolbox. [http://web.eecs.umich.edu/~fessler/code/]
Wang Z, Bovik AC: A universal image quality index. Signal Processing Letters, IEEE 2002,9(3):81–84.
Acknowledgment
The authors would like to thank Professor Feng Gao and Professor HuiJuan Zhao for providing micro-CT data.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
HL and XC conceived the study. HL implemented the studies and drafted the manuscript. XC, YW, and DY contributed to discussions and suggestions throughout this work. XC and DY supervised the study. ZZ and QZ designed and performed the experiments. All authors read and approved the final manuscript.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
To view a copy of this licence, visit https://creativecommons.org/licenses/by/4.0/.
The Creative Commons Public Domain Dedication waiver (https://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

{kind=link}
Cite this article
Li, H., Chen, X., Wang, Y. et al. Sparse CT reconstruction based on multi-direction anisotropic total variation (MDATV). BioMed Eng OnLine 13, 92 (2014). https://doi.org/10.1186/1475-925X-13-92
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1475-925X-13-92